When you have a data source you want access to, you often find that CData have a provider that can help with this issue. However you sometimes hit another issue with some of these providers when you want to get more than the initial data out of it. Examples of this could be that your REST provider by default only shows 100 rows or that it requires an external input for it to show anything.
This is where the use of an RSD schema file can help. It is essentially a way to control all get calls sent to the source. It is also a sort of programming language.
Contents
- How to generate an RSD file
- Add connection info to rsd file
- Add pagination to the files
- Using nested calls to get data from multiple pages
- Use Parameters
- Create an dynamic date range filter
- Links and files
How to generate an RSD file
Setup
The important parts to generate this is three things.
- You need to point at a file or URI.
- You need the feature Generate Schema Files set to one of the following options OnUse, OnStart and OnCreate
- Your Schema Location needs to be set to an existing folder.
Here is an image of the default look for an json provider, but it could be for anyone that have these fields.
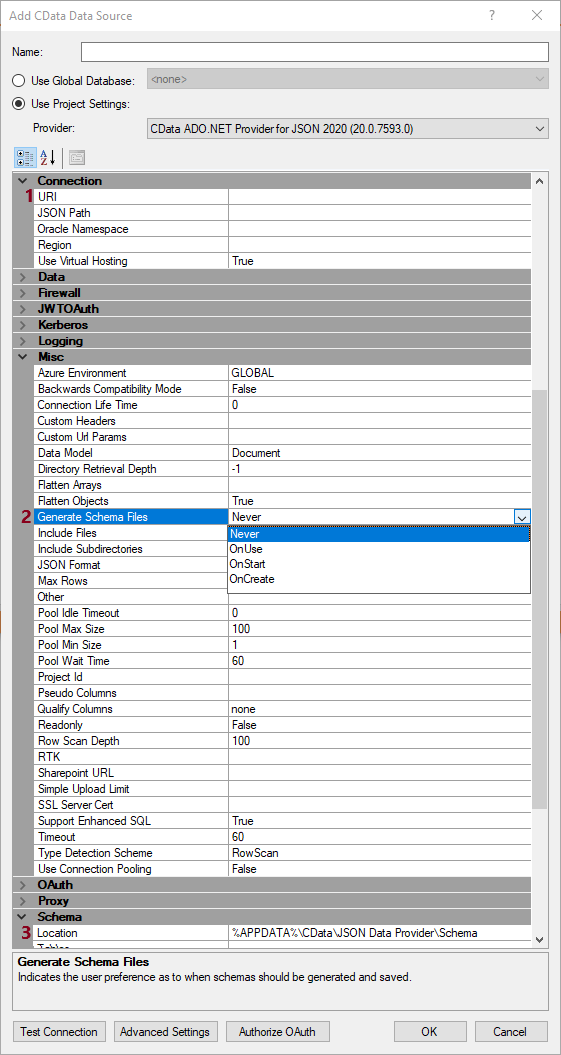
What schema generation option to use is dependent on a few things.
- Never: A schema file will never be generated.
- OnUse: A schema file will be generated the first time a table is referenced, provided the schema file for the table does not already exist.
- OnStart: A schema file will be generated at connection time for any tables that do not currently have a schema file.
- OnCreate: A schema file will be generated by when running a CREATE TABLE SQL query.
So if you have connection issues that the RSD file needs to handle, set it to OnStart, OnUse when you want to substitute the URI with the file and for this guide I don't see when we could use the OnCreate. OnUse is the one that is mainly used.
In regards to the location, there already is a default folder path, but consider that appdata is a folder that is under the specific user that is currently using TimeXtender. So if you have multiple environments and multiple users, add a folder that is sharable across these. If you have the environments on individual servers you either have to store the files on a shared drive or save these files on the same drive and folder on each server.
With these options set you can generate the file simply by synchronizing the data source.
An example of how it is done
If you want to try this out the following page can be used. https://gorest.co.in/
Like so.
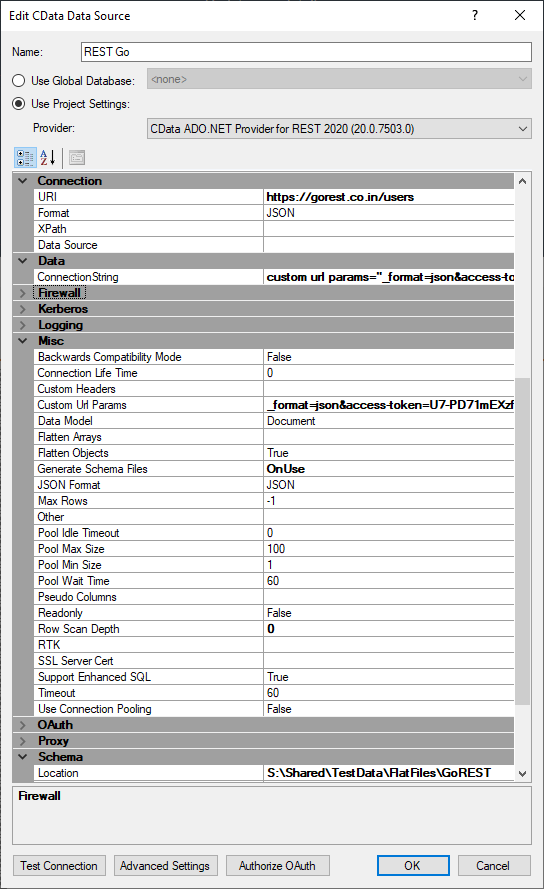
I did it for all the pages in the source. When I didn't want it to continue creating a data file every time I synchronized, I turned these fields off. This will only show you the ones you made a rsd file for.
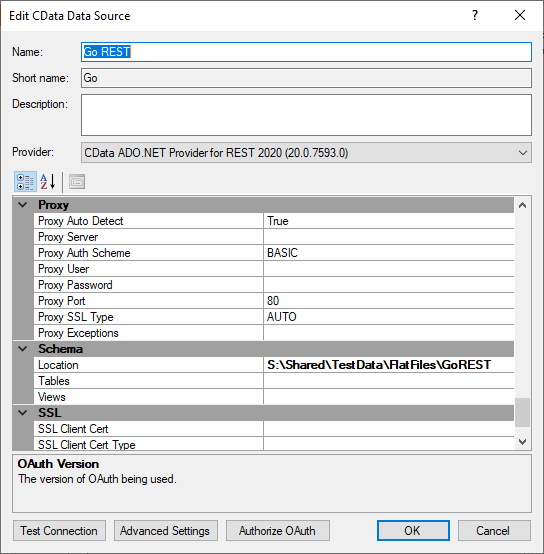

When one is generated it will look as follows in an text file provider. I also renamed the title from data to users and named the file users.rsd. Bonus info. When working with text files it can be hard to keep track of all of it. Therefore using an provider that can choose language is a big help. This for example is XML encoding.
Add connection info to rsd file
You can find some info about the options here jsonproviderGet
Also there have been updates to the guide for this by CData, so many of the things explained below is also present here SELECT Execution
CustomURLParams
You can use custom URL parameters by modifying attributes in the connection via the _connection object. For example:
<rsb:set attr="_connection.CustomUrlParams" value="field1=value1&field2=value2&field3=value3" />
So say that you wanted to add the access-token from the custom url field to the file. You would set it up as follows. You can generate the access-token from gorest here https://gorest.co.in/access-token
<rsp:set attr="_connection.CustomUrlParams" value="access-token=48ed584d0b694e0db651f7fb1e6846a9f3ce8c4c9889f5b5b5af1c5194d4e02e" />
Then it will be used by the file. You can also keep it in the CData setup like so in the image below.
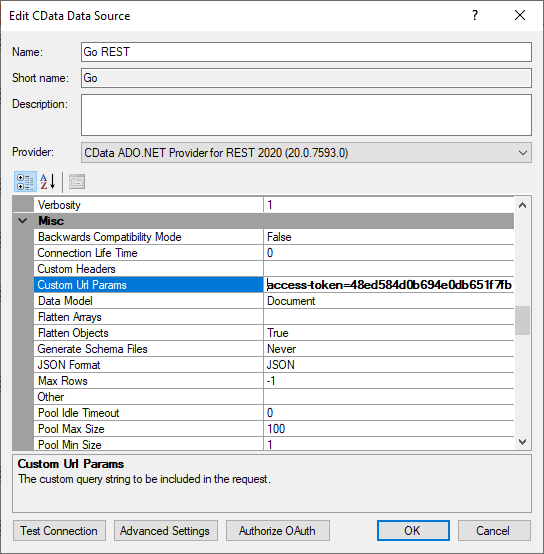
Though if you use this setting, you should add the custom setting before generating the rsd files.
Finally you can also just add it to the URL string like you would if you were to open it in a web browser.
<api:set attr="URI" value="https://gorest.co.in/public-api/users?access-token=48ed584d0b694e0db651f7fb1e6846a9f3ce8c4c9889f5b5b5af1c5194d4e02e" />
Custom Headers
You can do the same with custom headers and this may be more necessary, as the other part can be added in the url string and this can't.
The setup is as follows.
- Header:Name#: The name for each custom header to pass with the request.
- Header:Value#: The value for each custom header to pass with the request.
So that translates to this for example. It can set the file requested to be returned in JSON format.
<api:set attr="Header:Name#" value="Accept" />
<api:set attr="Header:Value#" value="application/json" />
More importantly you can authenticate the rsd file with this metod, say you want to add a baerer token you have generated.
<api:set attr="Header:Name#" value="Authorization" />
<api:set attr="Header:Value#" value="Bearer 1A_iJBHFUt3gPzkIc3Vi198PxHZ3M6n6OQsCehJ65en" />
It should be noted that this won't be auto updated this way, so you will need to use the normal OAuth metods explained in the REST guide to make it dynamic.
If you go through the initial link about the get command, there also are other methods that can be used the same way.
How it is done in the file
The important bits to remember are where in the file it is added, in what order, and how it is used.
Here is how it looks when you add the custom URL parameter to the user RSD file we created using the first method. I added it after the info area, but before the DataModel and the URI row.
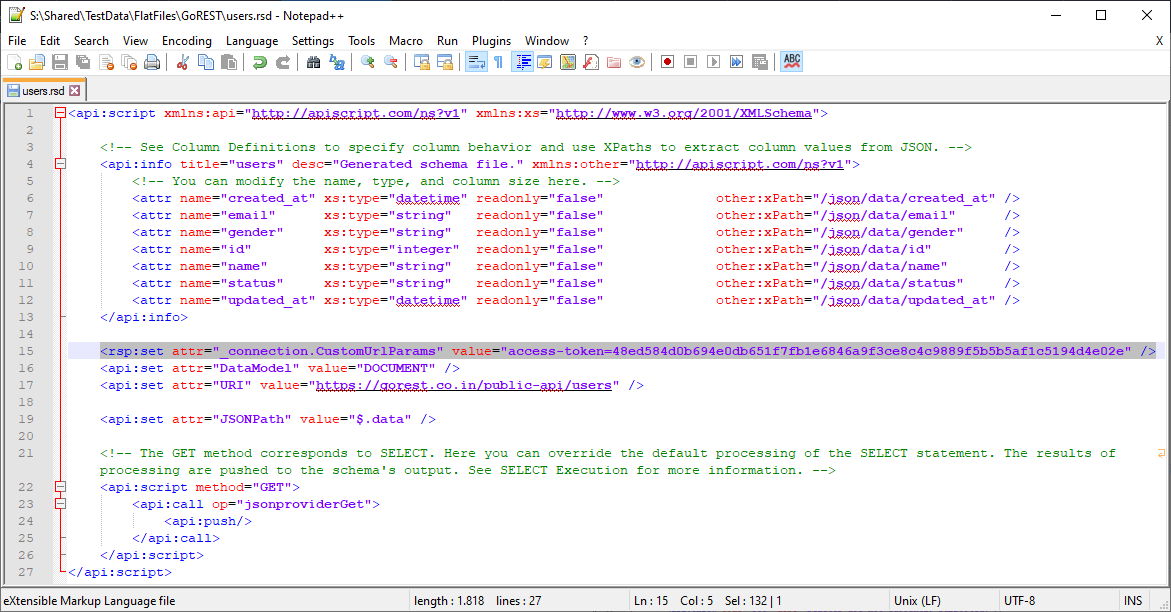
Now, this file doesn't need a bearer token to work, or an access token actually, but you can use the same procedure just explained, but with ParamName instead of Header:Name to achieve the same.
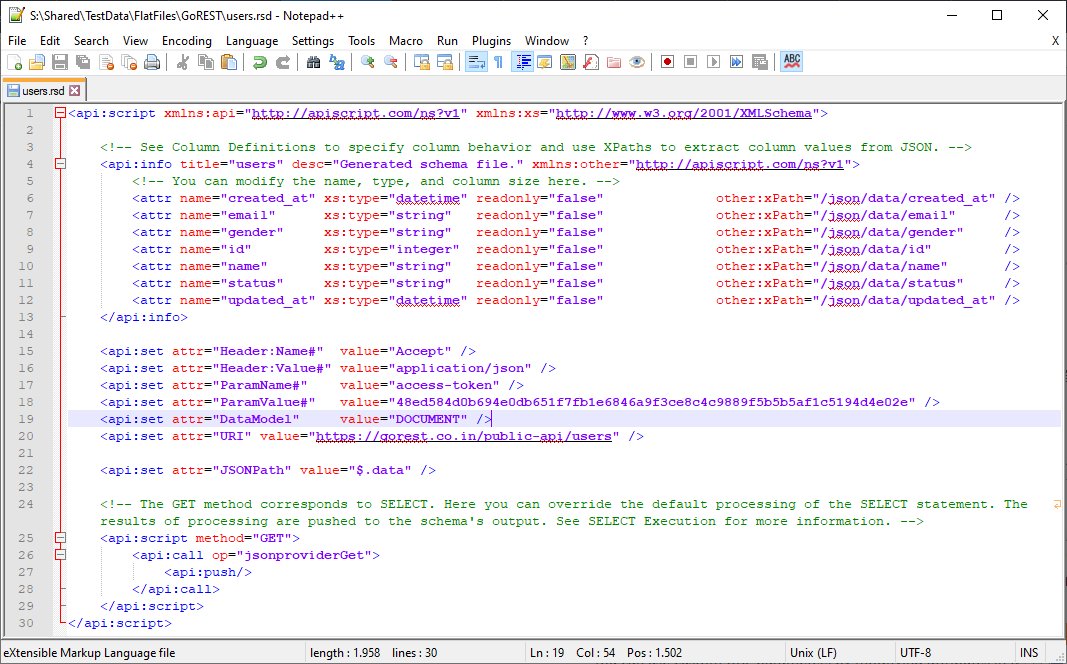
Add pagination to the files
Pagination is a method where you iterate through a number of pages until you hit the end and get all the data out of the API for a specific resource.
There are two ways of doing this and it depends on what your API supports.
One requirement is to add the following
<api:set attr="EnablePaging" value="true"/>
Add this after the <info> area but before the get calls.
Using this will make the paging work. So it should be added to all RSD files if you want to do multiple calls. The only time you do not need it is when you use the dummy fields as explained in the Using nested calls to get info from multiple pages section.
Record Offset
If the service provides a record offset query parameter to control paging, you can implement this by setting the name of the offset query parameter, the name of the page size query parameter, and the page size to be passed. Note that the page size parameter does not need to be set if there is no parameter to control this. In this case, you must set pagesize to the default page size.
<api:set attr="pageoffsetparam" value="offset" />
<api:set attr="pagesizeparam" value="limit" />
<api:set attr="pagesize" value="100" />
The offset and size parameter options may have different names, but these should be mentioned in the API documentation.
Page Number
Similar to record offset, if the service provides a query parameter that sets the page number, you can implement this by setting the name of the page number query parameter, the name of the page size query parameter, and the page size to be passed. Note that the page size parameter does not need to be set if there is no parameter to control this. In this case, you must set pagesize to the default page size.
<api:set attr="pagenumberparam" value="page" />
<api:set attr="pagesizeparam" value="pagesize" />
<api:set attr="pagesize" value="100" />
This is a new method, so it can possibly work for most of the options regarding page that have a page and pagesize or pagecount option in the API. So this may be used instead of the IF and Enum options explained below.
Push response header link method
If your API has the following setup. The proposed standard RFC-8288 is to include information about the current page in the HTTP header.
In more detail, the following information is included in the Header:
Per-Page: the number of results shown per pagePage: the currently displayed pageLink: a set of RFC-8288 encoded links to the first, next, previous, and last pages (if applicable).Total: the total number of results
Page
The following method is for the PushResponseHeader Page method.
- You push header names onto the end of the PushResponseHeader# input array, which will mark them to be saved.
- Set any other inputs and invoke jsonproviderGet / xmlproviderGet
- Read the result from the header: set of output attributes, which are named based on the inputs given to the push header array. For example, if you set the push headers so it contains the values [Per-Page, Page] then the header values will be set on the header:Per-Page and header:Page attributes of the output item.
<api:set attr="PushResponseHeader#" value="Page" />
...
<api:set attr="output.rows@next" value="[output.header:Page]" />
The previous also can be used to get the last page, then you can make a if statement where you will set the next page until you reach the last.
It could look something like this.
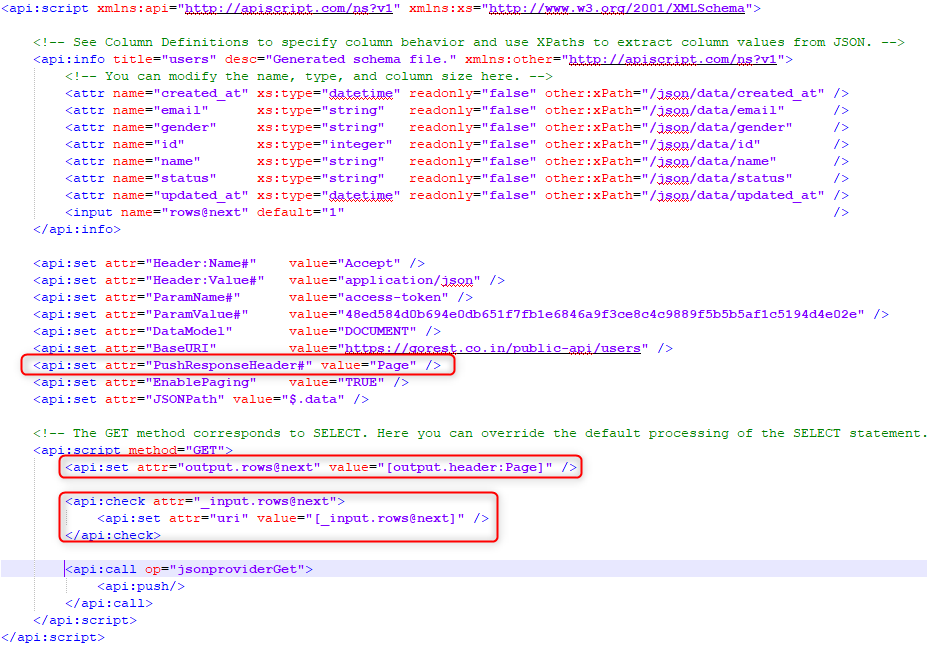
Remember that the GoREST provider doesn't use this, so you can't make this exact thing work.
Link
Another common occurrence is that you have an Link header in your metadata. Like what is common with OKTA, looking like what you can see below.
Link: <https://{yourOktaDomain}.com/api/v1/users?after=00ubfjQEMYBLRUWIEDKK>; rel="next", <https://{yourOktaDomain}.com/api/v1/users?after=00ub4tTFYKXCCZJSGFKM>; rel="self"
It actually is possible to use this to do pagination as well. It is a very simple setup as well.
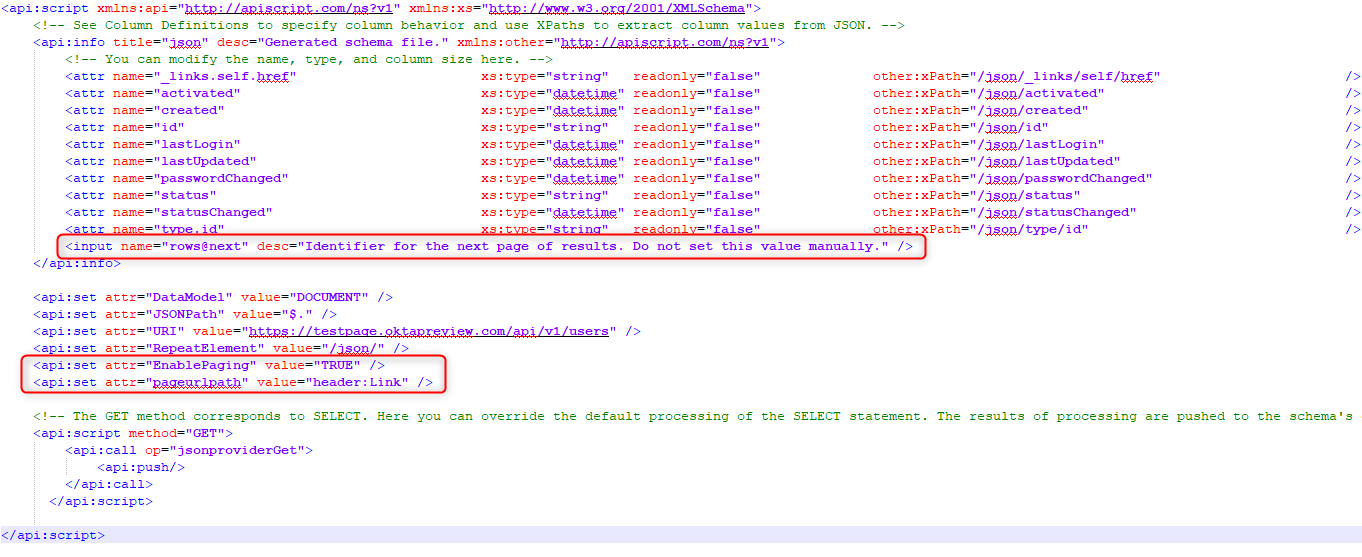
All I do is to add that it is to run with Paging, have an rows@next input option and have an pageurlpath attribute that is set to be of value Header:Link. The rest is controlled by the file, no need to add a if statement or enum loop.
Remember that the GoREST provider doesn't use this, so you can't make this exact thing work.
Next Page URL
If the next page URL is passed in the response body, set 'pageurlpath' to the XPath of the element.
<api:set attr="pageurlpath" value="/data/nextPage" />
This makes it real simple to make it work. One page that uses this method is swapi.dev
So here is how you would make pagination work for the people page.

I just added a repeat element and set enablepaging = true and added a pageurlpath that corresponds to the next page. I have added it and another method to achieve the same thing as people.rsd and People_RWNE.rsd
If and page method
To make the GoREST work with pagination you can set up an if statement that takes the last page and the current page and uses them to iterate through.
If we takes a look at one of them, like users for example.
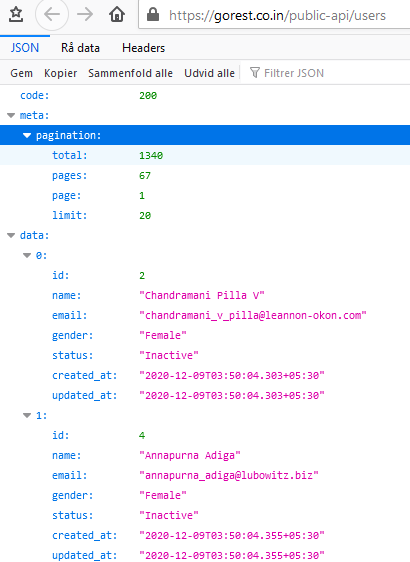
You can see that it has some pagination info on the top of the json data. What we want are the pages value and the page value to be added as variables in our code. To do so we can use the element mapping feature.
<api:set attr="ElementMapPath#" value="xpath to field" />
<api:set attr="ElementMapPath#" value="name" />
So to convert this to what we want to use from the GoREST page, we get this.
<api:set attr="ElementMapPath#" value="/json/meta/pagination/pages" />
<api:set attr="ElementMapName#" value="pages" />
<api:set attr="ElementMapPath#" value="/json/meta/pagination/page" />
<api:set attr="ElementMapName#" value="page" />
Besides this we also want to tell that the file is using pagination, so we will add the following
<api:set attr="EnablePaging" value="TRUE" />
We will also add a input field, that will contain the current page you are attempting to add get data from.
<input name="rows@next" default="1" />
We set up the URI with the updated page info, but this is something we do in the script get method area.
<api:set attr="URI" value="[BaseURI]?page=[_input.rows@next]" />
Finally we set up the if statement and add the info to the output variable that we finally push to get the data back. Note that I also use the function Add() to add a number to the current page and get the next one.
<api:call op="jsonproviderGet">
<api:if attr="page" value="[pages]" operator="lessthan">
<api:set attr="rows@next" value="[page | Add(1)]" />
</api:if>
<api:push/>
</api:call>
Finally we have the whole document done. You can see how it should look here.
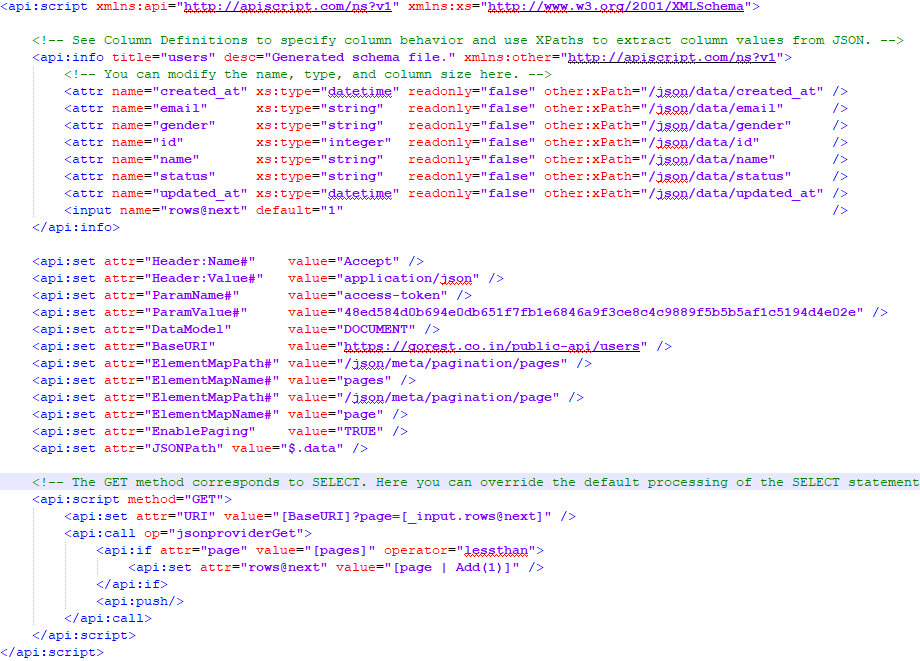
After doing the changes it is not necessary to deploy or synchronize anything, just executing the table/task is enough.
If you want to see what pages it iterates through, add a log to your setup, like so.
Don't set the verbosity too high as it will then add all the data it pulls from the source to the file as well as the store. The following is also a good way to see, what happens when it doesn't work.
Finally when executed it will contain this amount of data.
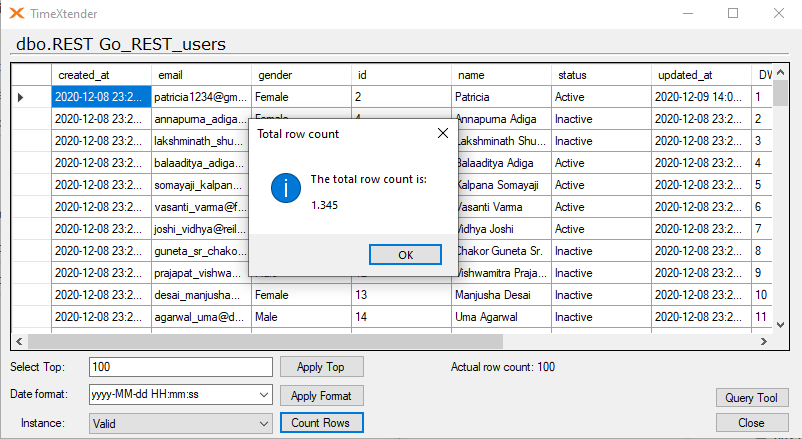
Enum and page method
This method is somewhat different, in that it uses an enum loop to go through the pages.
Normally I would not use it for a single page get as this, but when you use a nested get calls. More of that in the next paragraph.
The major change to this is that we now use input and output of our calls, which makes it possible to use info from a previous call to the next. Additionally it is an requirement that all the fields that are used as part of all the fields you set.
<api:set attr="in.Header:Name#" value="Accept"/>
<api:set attr="in.Header:Value#" value="application/json"/>
<api:set attr="in.DataModel" value="DOCUMENT"/>
<api:set attr="in.JSONPath" value="$.data"/>
<api:set attr="in.EnablePaging" value="TRUE"/>
<api:set attr="in.ParamName#" value="access-token"/>
<api:set attr="in.ParamValue#" value="48ed584d0b694e0db651f7fb1e6846a9f3ce8c4c9889f5b5b5af1c5194d4e02e"/>
<api:set attr="in.Page" value="1"/>
<api:set attr="in.PageCount" value="4"/>
<api:set attr="in.BaseURI" value="https://gorest.co.in/public-api/users?page={page}"/>
<api:set attr="in.ElementMapPath#" value="/json/meta/pagination/pages"/>
<api:set attr="in.ElementMapName#" value="pages"/>
If any of the fields are not set up with in. in front of it it will not work.
The next step is in the get method where I set the URI to contain the base URI and replacing the {page} with a 1 number.
<api:set attr="in.URI" value="[in.BaseURI | replace('{page}', 1)]"/>
The next step is an initial call command that uses the previously generated uri. notice that I use in="in" and out="out" in the call command. This is then used to set the output value of pages to be contained in the PageCount.
<api:call op="jsonproviderGet" in="in" out="out">
<api:set attr="in.PageCount" value="[out.pages]"/>
</api:call>
The reason for this is to get the maximum number of pages from the metadata and then use it as the endpoint of the enum range. In the enum itself I first set the current step in the range _value and sets it to the Page. Then I use that to replace {page} with the current range number and in the call i push the output with the item="out" command.
<api:enum range="1..[in.PageCount]">
<api:set attr="in.Page" value="[_value]"/>
<api:set attr="in.URI" value="[in.BaseURI | replace('{page}', [in.Page])]"/>
<api:call op="jsonproviderGet" in="in" out="out">
<api:push item="out"/>
</api:call>
</api:enum>
I can avoid using PageCount and Page in this, by using in.pages and _value in the range and uri setting areas, but since I set it with default values in the initial set, they will make the calls work despite the values being empty in the source. This is a good safeguard, especially when you use nested calls.
In the end the file will look like this.
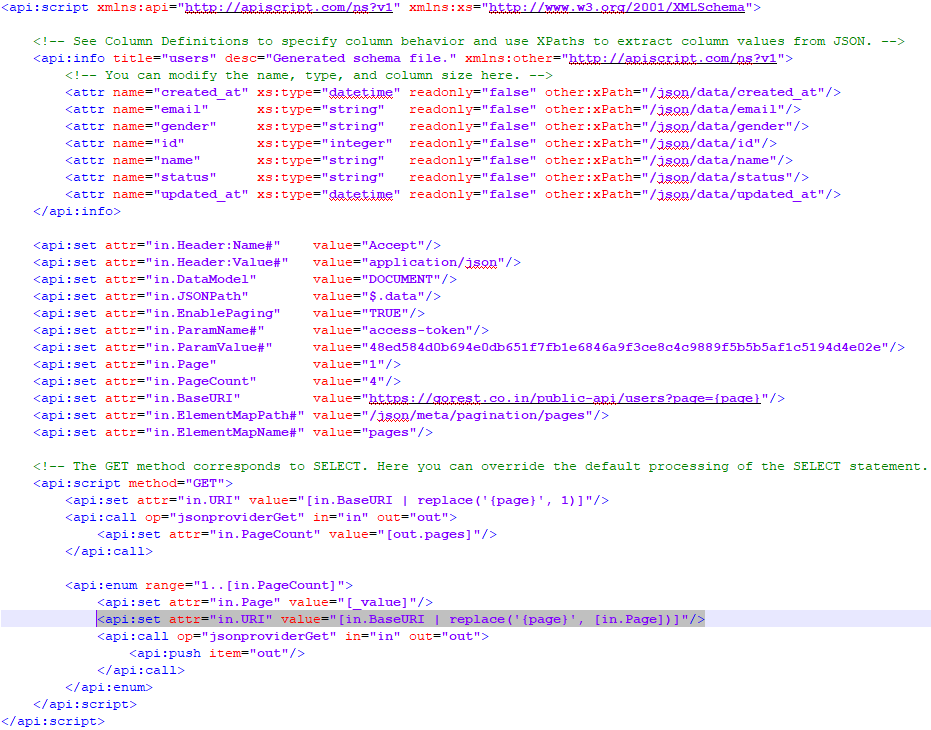
Using nested calls to get data from multiple pages
The usual issue for when you use this is the following. You have some users, which you can get, but you also want to get the posts of those users. So something like this.
https://gorest.co.in/public-api/users/{userid}/posts
That only gave the info from one customer, but you want to get all users and all their posts in one table. This is because there is no way to just get all posts with a relation to the user or similar. This can even be more extreme, where you also wants to get the comments on the posts as well. More on that later, but first the posts of the users.
One nested call
UPDATE
I recently learned an simpler way to do this that takes way less space in the RSD file and makes it easier to survey. I still have the old method for reference, as it still works and also incorporates the pagination in to the method.
New method
I found that you do not need to specify all the fields you want to use with an ElementMapPath and ElementMapName and setting the xPath to be equal to dummy. All needed is that you have the following command in the file.
<api:set attr="stopin.EnablePaging" value="TRUE" />
I have this rest call I need to do to get a list of stops on a transport. There is no need for pagination it will give all of the stops in one call. The issue is that to get a stop I need to specify a file id. I have a rest call that can give me all these ids. So I just need to mix them in a nested call to make it iterate over each file id.
First I need to define all the fields.
<api:info title="GetAllStops" desc="Generated schema file." xmlns:other="http://apiscript.com/ns?v1">
<!-- You can modify the name, type, and column size here. -->
<attr name="country" xs:type="string" readonly="false" other:xPath="/json/result/entity/stops/country" />
<attr name="id" xs:type="string" readonly="false" other:xPath="/json/result/entity/stops/id" />
<attr name="lastModificationTime" xs:type="datetime" readonly="false" other:xPath="/json/result/entity/stops/lastModificationTime" />
<attr name="lastModifierUserId" xs:type="integer" readonly="false" other:xPath="/json/result/entity/stops/lastModifierUserId" />
<attr name="mobileNumber" xs:type="string" readonly="false" other:xPath="/json/result/entity/stops/mobileNumber" />
<attr name="orderNumber" xs:type="integer" readonly="false" other:xPath="/json/result/entity/stops/orderNumber" />
<attr name="products" xs:type="string" readonly="false" other:xPath="/json/result/entity/stops/products" />
<attr name="telephoneNumber" xs:type="decimal" readonly="false" other:xPath="/json/result/entity/stops/telephoneNumber" />
<attr name="tenantId" xs:type="integer" readonly="false" other:xPath="/json/result/entity/stops/tenantId" />
</api:info>
Notice the xpath which points to the fields values. These fields are all from the same call.
First part is this.
<api:set attr="urlbase" value="https://webpage.com/api/services/app/Transport"/>
I have an URLBase, which is the part of the url both calls will share I use this in the URITemplate to specify the uri for the call to get the file ids.
Then I set up the necessary parts for the call to get the list of file ids.
<api:set attr="filein.DataModel" value="DOCUMENT" />
<api:set attr="filein.JSONPath" value="$.result.items" />
<api:set attr="filein.URITemplate" value="[urlbase]/GetAll"/>
<api:set attr="filein.ElementMapPath#" value="/json/result/items/id" />
<api:set attr="filein.ElementMapName#" value="file_id" />
I state the data model type and the JSON path. Notice that it is not the same as in the fields of the table. I use the ElementMap option to map the file_id field from the call. Also all of these are set to be in the filein item variable.
The third step is to set up the getallstops URI call.
<api:set attr="stopin.DataModel" value="DOCUMENT" />
<api:set attr="stopin.EnablePaging" value="TRUE" />
<api:set attr="stopin.JSONPath" value="$.result.entity.stops" />
<api:set attr="stopin.URITemplate" value="[urlbase]/GetAllStops/{file_id}"/>
It is essentially the same as before, the URITemplate is different and is containing {file_id} which is the place holder for where the real file id will be added, the enablepaging part is set here as to avoid having to individually map all the fields. The JSONPath is the same as the one in the info area. This area is set to be in the stopin item variable instead.
Then I set up my first call.
<api:script method="GET">
<api:set attr="filein.URI" value="[filein.URITemplate]"/>
<api:call op="jsonproviderGet" in="filein" out="fileout">
...
</api:call>
</api:script>
I make the filenin version of the URITemplate equal to filein.URI and then in the call I have set the input to filein and output to fileout.
When I have done my call I will get the file ids to use those in the next call I will have to set the value and add it to the URI.
<api:set attr="filein.file_id" value="[fileout.file_id]" />
<api:set attr="stopin.URI" value="[stopin.URITemplate | replace('{file_id}', [filein.file_id])]"/>
You can see that i set the fileout file id to be filein.file_id and then I use that value in the stopin URI where I also add a Replace() command to swap the {file_id} with the real file id.
Once this is done I run the second call inside the first one.
<api:call op="jsonproviderGet" in="stopin" out="stopout">
<api:set attr="out.country" value="[stopout.country | allownull()]"/>
<api:set attr="out.id" value="[stopout.id | allownull()]"/>
<api:set attr="out.lastModificationTime" value="[stopout.lastModificationTime | allownull()]"/>
<api:set attr="out.lastModifierUserId" value="[stopout.lastModifierUserId | allownull()]"/>
<api:set attr="out.mobileNumber" value="[stopout.mobileNumber | allownull()]"/>
<api:set attr="out.orderNumber" value="[stopout.orderNumber | allownull()]"/>
<api:set attr="out.products" value="[stopout.products | allownull()]"/>
<api:set attr="out.telephoneNumber" value="[stopout.telephoneNumber | allownull()]"/>
<api:set attr="out.tenantId" value="[stopout.tenantId | allownull()]"/>
<api:push item="out"/>
</api:call>
I set the stopin as the input and the stopout as the output. Then I map each field individually under the out item variable. and then I push the out variable. Normally you would push the stopout item variable, but doing this resets the mapping and without this you can experience that it will put the field values in the wrong places. This is also why I have a mapping of each individual field, this part can be skipped and can be seen as an optional bonus.
Here below is the whole file with all the areas added. It is also an attached document as GetAllStops.RSD.
<api:script xmlns:api="http://apiscript.com/ns?v1" xmlns:xs="http://www.w3.org/2001/XMLSchema">
<!-- See Column Definitions to specify column behavior and use XPaths to extract column values from JSON. -->
<api:info title="GetAllStops" desc="Generated schema file." xmlns:other="http://apiscript.com/ns?v1">
<!-- You can modify the name, type, and column size here. -->
<attr name="country" xs:type="string" readonly="false" other:xPath="/json/result/entity/stops/country" />
<attr name="id" xs:type="string" readonly="false" other:xPath="/json/result/entity/stops/id" />
<attr name="lastModificationTime" xs:type="datetime" readonly="false" other:xPath="/json/result/entity/stops/lastModificationTime" />
<attr name="lastModifierUserId" xs:type="integer" readonly="false" other:xPath="/json/result/entity/stops/lastModifierUserId" />
<attr name="mobileNumber" xs:type="string" readonly="false" other:xPath="/json/result/entity/stops/mobileNumber" />
<attr name="orderNumber" xs:type="integer" readonly="false" other:xPath="/json/result/entity/stops/orderNumber" />
<attr name="products" xs:type="string" readonly="false" other:xPath="/json/result/entity/stops/products" />
<attr name="telephoneNumber" xs:type="decimal" readonly="false" other:xPath="/json/result/entity/stops/telephoneNumber" />
<attr name="tenantId" xs:type="integer" readonly="false" other:xPath="/json/result/entity/stops/tenantId" />
</api:info>
<api:set attr="urlbase" value="https://webpage.com/api/services/app/Transport"/>
<api:set attr="filein.DataModel" value="DOCUMENT" />
<api:set attr="filein.JSONPath" value="$.result.items" />
<api:set attr="filein.URITemplate" value="[urlbase]/GetAll"/>
<api:set attr="filein.ElementMapPath#" value="/json/result/items/id" />
<api:set attr="filein.ElementMapName#" value="file_id" />
<api:set attr="stopin.DataModel" value="DOCUMENT" />
<api:set attr="stopin.EnablePaging" value="TRUE" />
<api:set attr="stopin.JSONPath" value="$.result.entity.stops" />
<api:set attr="stopin.URITemplate" value="[urlbase]/GetAllStops/{file_id}"/>
<!-- The GET method corresponds to SELECT. Here you can override the default processing of the SELECT statement. The results of processing are pushed to the schema's output. See SELECT Execution for more information. -->
<api:script method="GET">
<api:set attr="filein.URI" value="[filein.URITemplate]"/>
<api:call op="jsonproviderGet" in="filein" out="fileout">
<api:set attr="filein.file_id" value="[fileout.file_id]" />
<api:set attr="stopin.URI" value="[stopin.URITemplate | replace('{file_id}', [filein.file_id])]"/>
<api:call op="jsonproviderGet" in="stopin" out="stopout">
<api:set attr="out.country" value="[stopout.country | allownull()]"/>
<api:set attr="out.id" value="[stopout.id | allownull()]"/>
<api:set attr="out.lastModificationTime" value="[stopout.lastModificationTime | allownull()]"/>
<api:set attr="out.lastModifierUserId" value="[stopout.lastModifierUserId | allownull()]"/>
<api:set attr="out.mobileNumber" value="[stopout.mobileNumber | allownull()]"/>
<api:set attr="out.orderNumber" value="[stopout.orderNumber | allownull()]"/>
<api:set attr="out.products" value="[stopout.products | allownull()]"/>
<api:set attr="out.telephoneNumber" value="[stopout.telephoneNumber | allownull()]"/>
<api:set attr="out.tenantId" value="[stopout.tenantId | allownull()]"/>
<api:push item="out"/>
</api:call>
</api:call>
</api:script>
</api:script>
Old method
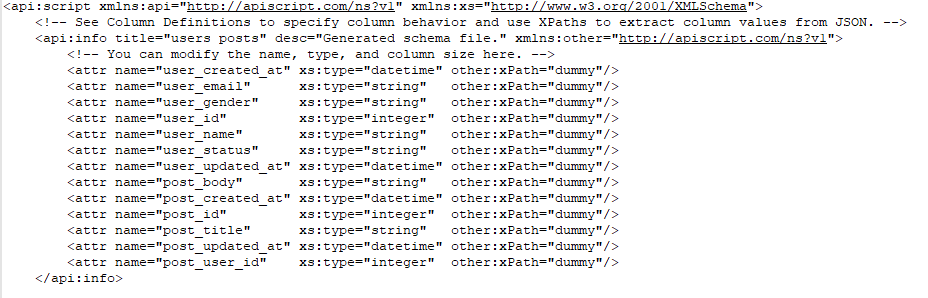
The first step is to mix the fields you want from the users and the nested one posts. I have also set a user_ or post_ in front of all the names, as some fields have the same names. Additionally I have also removed the specific xpath and set it to be a dummy. We will be filling the field on a later set operation.
<api:info title="users posts" desc="Generated schema file." xmlns:other="http://apiscript.com/ns?v1">
<!-- You can modify the name, type, and column size here. -->
<attr name="user_created_at" xs:type="datetime" other:xPath="dummy"/>
<attr name="user_email" xs:type="string" other:xPath="dummy"/>
<attr name="user_gender" xs:type="string" other:xPath="dummy"/>
<attr name="user_id" xs:type="integer" other:xPath="dummy"/>
<attr name="user_name" xs:type="string" other:xPath="dummy"/>
<attr name="user_status" xs:type="string" other:xPath="dummy"/>
<attr name="user_updated_at" xs:type="datetime" other:xPath="dummy"/>
<attr name="post_body" xs:type="string" other:xPath="dummy"/>
<attr name="post_created_at" xs:type="datetime" other:xPath="dummy"/>
<attr name="post_id" xs:type="integer" other:xPath="dummy"/>
<attr name="post_title" xs:type="string" other:xPath="dummy"/>
<attr name="post_updated_at" xs:type="datetime" other:xPath="dummy"/>
<attr name="post_user_id" xs:type="integer" other:xPath="dummy"/>
</api:info>
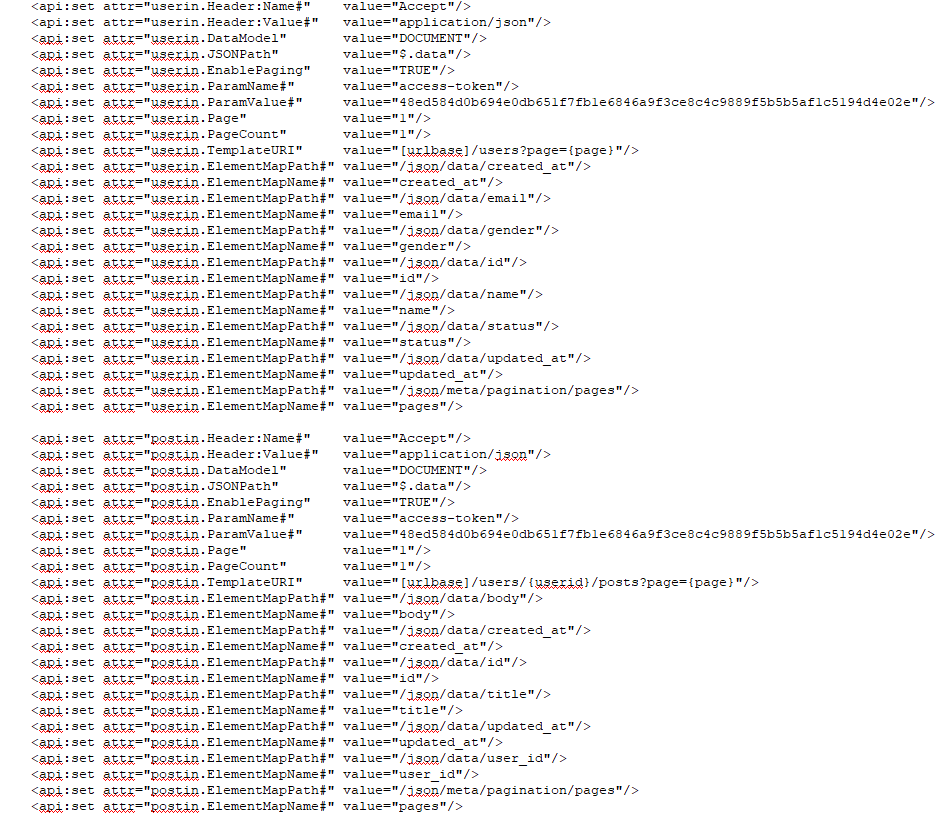
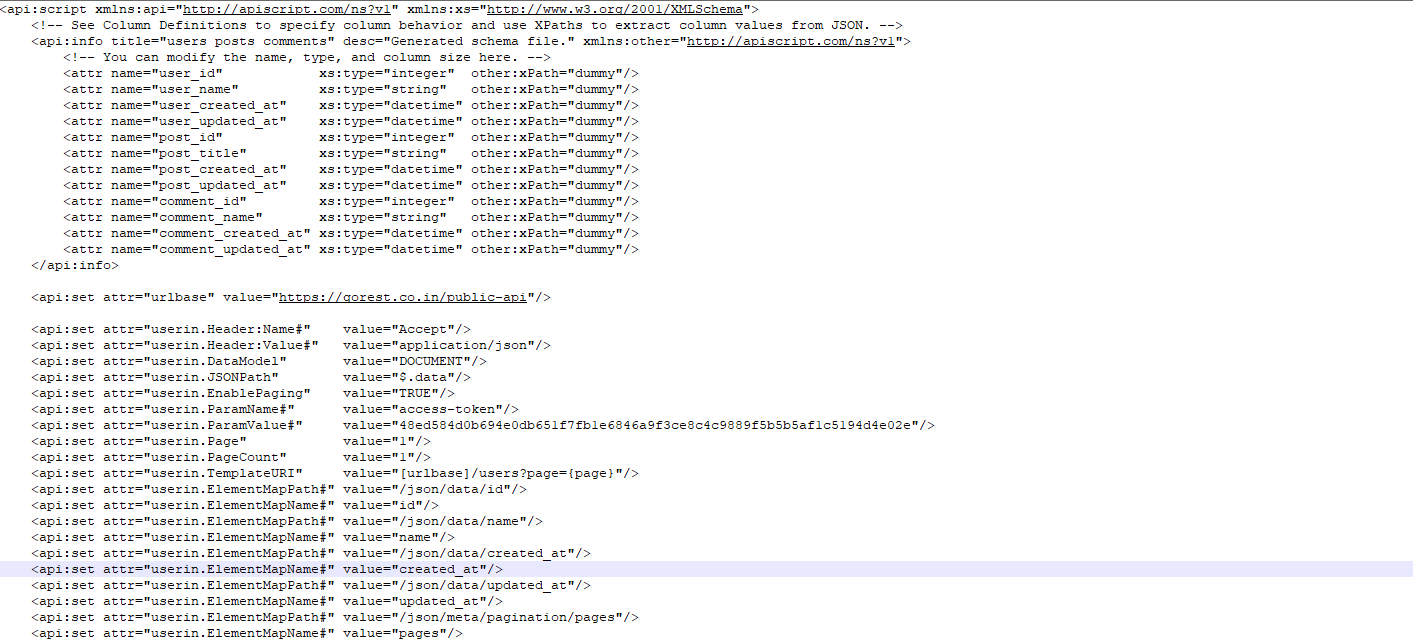
Each field are set as an ElementMapPath and ElementMapName for the specific URI call. It also uses a specific input name to avoid pointing to the same XPath location. First I set up an urlbase, as that part is shared between the two URI's i will use.
<api:set attr="urlbase" value="https://gorest.co.in/public-api"/>
Here it is for users which is also containing the same info as from the users file.
<api:set attr="userin.Header:Name#" value="Accept"/>
<api:set attr="userin.Header:Value#" value="application/json"/>
<api:set attr="userin.DataModel" value="DOCUMENT"/>
<api:set attr="userin.JSONPath" value="$.data"/>
<api:set attr="userin.EnablePaging" value="TRUE"/>
<api:set attr="userin.ParamName#" value="access-token"/>
<api:set attr="userin.ParamValue#" value="48ed584d0b694e0db651f7fb1e6846a9f3ce8c4c9889f5b5b5af1c5194d4e02e"/>
<api:set attr="userin.Page" value="1"/>
<api:set attr="userin.PageCount" value="1"/>
<api:set attr="userin.TemplateURI" value="[urlbase]/users?page={page}"/>
<api:set attr="userin.ElementMapPath#" value="/json/data/created_at"/>
<api:set attr="userin.ElementMapName#" value="created_at"/>
<api:set attr="userin.ElementMapPath#" value="/json/data/email"/>
<api:set attr="userin.ElementMapName#" value="email"/>
<api:set attr="userin.ElementMapPath#" value="/json/data/gender"/>
<api:set attr="userin.ElementMapName#" value="gender"/>
<api:set attr="userin.ElementMapPath#" value="/json/data/id"/>
<api:set attr="userin.ElementMapName#" value="id"/>
<api:set attr="userin.ElementMapPath#" value="/json/data/name"/>
<api:set attr="userin.ElementMapName#" value="name"/>
<api:set attr="userin.ElementMapPath#" value="/json/data/status"/>
<api:set attr="userin.ElementMapName#" value="status"/>
<api:set attr="userin.ElementMapPath#" value="/json/data/updated_at"/>
<api:set attr="userin.ElementMapName#" value="updated_at"/>
<api:set attr="userin.ElementMapPath#" value="/json/meta/pagination/pages"/>
<api:set attr="userin.ElementMapName#" value="pages"/>
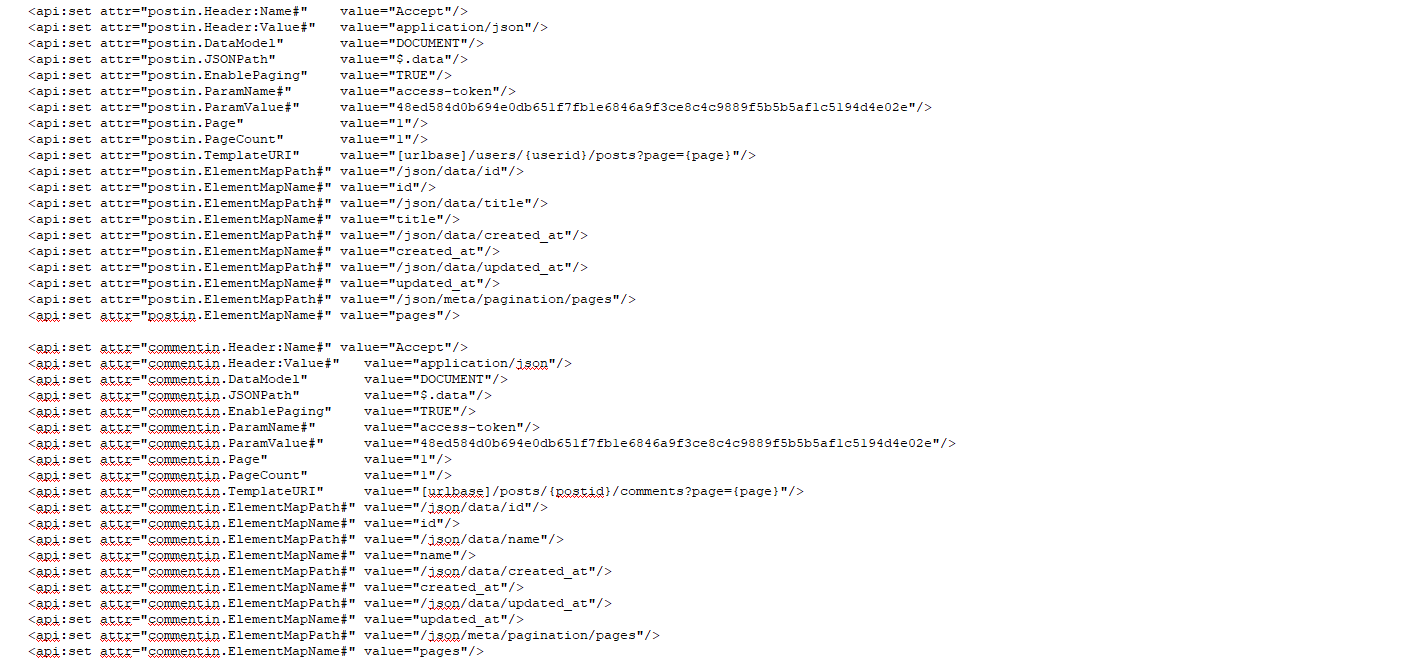
Here it is for posts, notice that it essentially is the same, despite the field names being different.
<api:set attr="postin.Header:Name#" value="Accept"/>
<api:set attr="postin.Header:Value#" value="application/json"/>
<api:set attr="postin.DataModel" value="DOCUMENT"/>
<api:set attr="postin.JSONPath" value="$.data"/>
<api:set attr="postin.EnablePaging" value="TRUE"/>
<api:set attr="postin.ParamName#" value="access-token"/>
<api:set attr="postin.ParamValue#" value="48ed584d0b694e0db651f7fb1e6846a9f3ce8c4c9889f5b5b5af1c5194d4e02e"/>
<api:set attr="postin.Page" value="1"/>
<api:set attr="postin.PageCount" value="1"/>
<api:set attr="postin.TemplateURI" value="[urlbase]/users/{userid}/posts?page={page}"/>
<api:set attr="postin.ElementMapPath#" value="/json/data/body"/>
<api:set attr="postin.ElementMapName#" value="body"/>
<api:set attr="postin.ElementMapPath#" value="/json/data/created_at"/>
<api:set attr="postin.ElementMapName#" value="created_at"/>
<api:set attr="postin.ElementMapPath#" value="/json/data/id"/>
<api:set attr="postin.ElementMapName#" value="id"/>
<api:set attr="postin.ElementMapPath#" value="/json/data/title"/>
<api:set attr="postin.ElementMapName#" value="title"/>
<api:set attr="postin.ElementMapPath#" value="/json/data/updated_at"/>
<api:set attr="postin.ElementMapName#" value="updated_at"/>
<api:set attr="postin.ElementMapPath#" value="/json/data/user_id"/>
<api:set attr="postin.ElementMapName#" value="user_id"/>
<api:set attr="postin.ElementMapPath#" value="/json/meta/pagination/pages"/>
<api:set attr="postin.ElementMapName#" value="pages"/>
So now our task is to run the two calls in the correct order, so you first get all users and then populates the remaining fields. The main thing is the correct order of the call of the URI's.
<api:set attr="userin.URI" value="[userin.TemplateURI | replace('{page}', 1)]"/>
<api:call op="jsonproviderGet" in="userin" out="userout">
<api:set attr="userin.PageCount" value="[userout.pages]"/>
</api:call>
<api:enum range="1..[userin.PageCount]">
<api:set attr="userin.Page" value="[_value]"/>
<api:set attr="userin.URI" value="[userin.TemplateURI | replace('{page}', [userin.Page])]"/>
<api:call op="jsonproviderGet" in="userin" out="userout">
<api:set attr="postin.URI" value="[postin.TemplateURI | replace('{userid}', [userout.id]) | replace('{page}', 1)]"/>
<api:call op="jsonproviderGet" in="postin" out="postout">
<api:set attr="postin.PageCount" value="[postout.pages]"/>
</api:call>
<api:enum range="1..[postin.PageCount]">
<api:set attr="postin.Page" value="[_value]"/>
<api:set attr="postin.URI" value="[postin.TemplateURI | replace('{userid}', [userout.id]) | replace('{page}', [postin.Page])]"/>
<api:call op="jsonproviderGet" in="postin" out="postout">
...
</api:call>
</api:enum>
</api:call>
</api:enum>
When you reach the last level of the nesting we will set the dummy values with the realized data from the calls. I do not use the same output for those as it will be a sort of reset of them on each call in the range. The Allow Null function on the post fields is to make it work if those fields were to be empty because an user had no posts made.
<api:call op="jsonproviderGet" in="postin" out="postout">
<api:set attr="out.user_created_at" value="[userout.created_at]"/>
<api:set attr="out.user_email" value="[userout.email]"/>
<api:set attr="out.user_gender" value="[userout.gender]"/>
<api:set attr="out.user_id" value="[userout.id]"/>
<api:set attr="out.user_name" value="[userout.name]"/>
<api:set attr="out.user_status" value="[userout.status]"/>
<api:set attr="out.user_updated_at" value="[userout.updated_at]"/>
<api:set attr="out.post_body" value="[postout.body | allownull()]"/>
<api:set attr="out.post_created_at" value="[postout.created_at | allownull()]"/>
<api:set attr="out.post_id" value="[postout.id | allownull()]"/>
<api:set attr="out.post_title" value="[postout.title | allownull()]"/>
<api:set attr="out.post_updated_at" value="[postout.updated_at | allownull()]"/>
<api:set attr="out.post_user_id" value="[postout.user_id | allownull()]"/>
<api:push item="out"/>
</api:call>
Here is how it looks when it is all done.
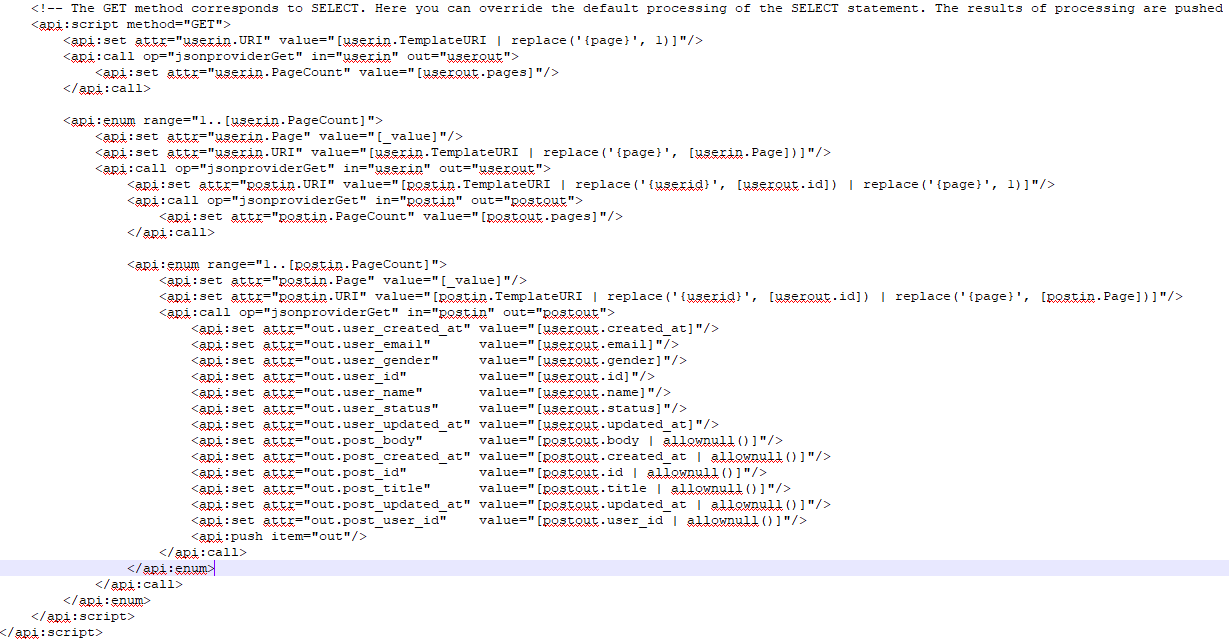
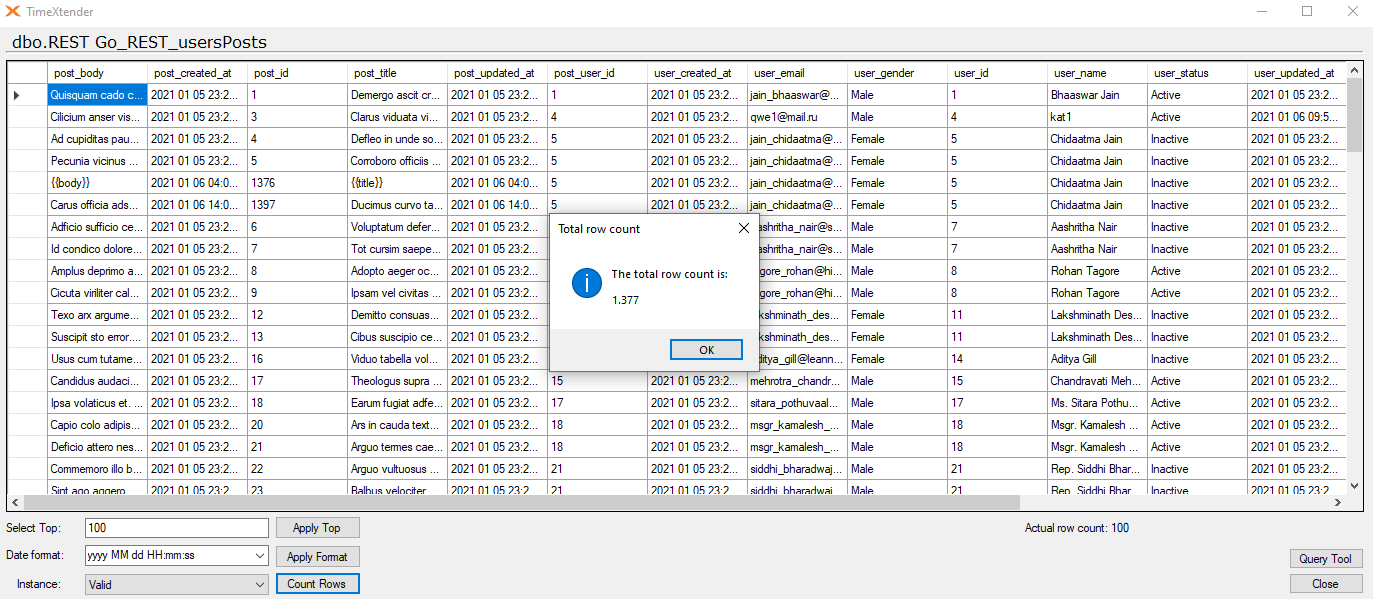
Using this as a table and executing this specifically is not fast, there is a lot of users and most have posts on them, so this will run for a while. You can make it more simple by only using the field you need user_id from the other uri.
More than one nested call
The procedure is the same as before. You add the fields you want as dummies, add the in fields same way as for the others, does another call to get the last page of the call and in the end another call where you set the dummies.
Here below is the full file for that merging users, posts and comments into one.
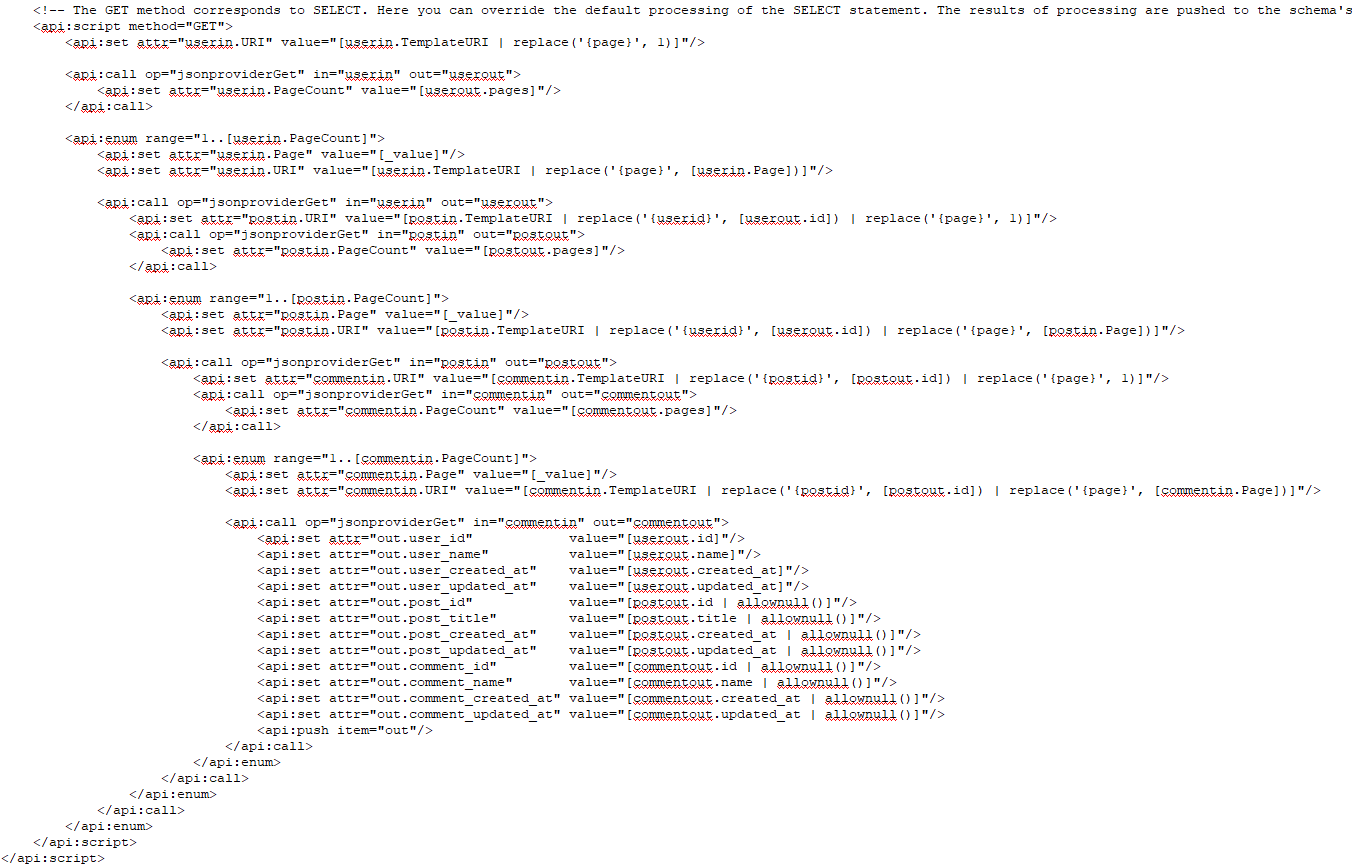
As you can see the only difference is that we go to another lower level doing the same again, this time the only difference is replace('{postid}', [postout.id]) instead of user.
Here is how it looks in TX when all rows are in.
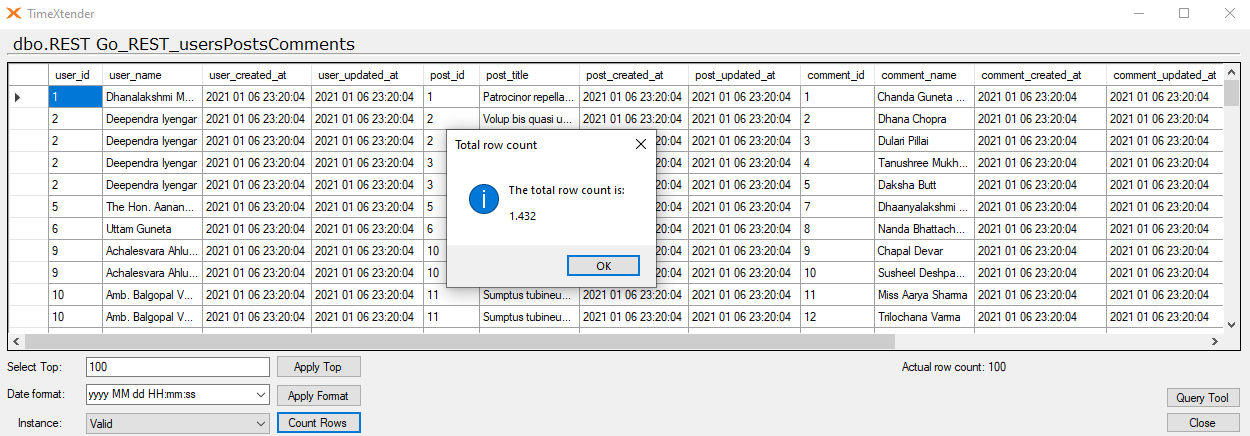
Use parameters
This specific method only works for Business Units
You can also use an parameter to make it work and it can be that you want the parameter to be something dynamic, or something you apply in TimeXtender instead of in the RSD file.
Using fixer.io we can pull out data, but if we want to get data from a specific day the uri would look something like this.
http://data.fixer.io/api/2020-03-15?access_key=522b683569a91b66be6be214027b47bf
So it doesn't work without a date added after the api/. I want it to show current date or similar. I generate an RSD file for the source and adds two changes. Here is the RSD script.
<api:script xmlns:api="http://apiscript.com/ns?v1" xmlns:xs="http://www.w3.org/2001/XMLSchema">
<!-- See Column Definitions to specify column behavior and use XPaths to extract column values from JSON. -->
<api:info title="Currencies" desc="Generated schema file." xmlns:other="http://apiscript.com/ns?v1">
<!-- You can modify the name, type, and column size here. -->
<attr name="base_currency" xs:type="string" other:xPath="base"/>
<attr name="date" xs:type="string" other:xPath="date"/>
<attr name="historical" xs:type="boolean" other:xPath="historical" />
<attr name="exchange_rate_to_USD" xs:type="string" other:xPath="rates/USD"/>
<attr name="exchange_rate_to_GBP" xs:type="string" other:xPath="rates/GBP"/>
<attr name="exchange_rate_to_AUD" xs:type="string" other:xPath="rates/AUD"/>
<attr name="timestamp" xs:type="integer" other:xPath="timestamp"/>
<input name="datein" xs:type="string" default="2019-01-01"/>
</api:info>
<!-- The GET method corresponds to SELECT. Here you can override the default processing of the SELECT statement. The results of processing are pushed to the schema's output. See SELECT Execution for more information. -->
<api:script method="GET">
<api:check attr="_input.datein">
<api:set attr="URI" value="http://data.fixer.io/api/[_input.datein]?access_key=522b683569a91b66be6be214027b47bf"/>
</api:check>
<api:call op="jsonproviderGet">
<api:push/>
</api:call>
</api:script>
</api:script>
The two changes are <input> and <api:check>
The input sets the datein equal an specific date, or the default value. The default is necessary, or the file will fail.
Having this file, it is possible to use it a couple of ways.
You can use it in a query like so.

Or in a data selection rule like so. Remember that you can't choose the datein field in a list you will have to type it manually.

If the rest provider only works if you provide a filter like from date and to date you can also add custom url parameters and use them the same way. Such as this.
<input name="from" xs:type="string" default="2019-01-01"/>
<input name="to" xs:type="string" default="2020-01-01"/>
<rsb:set attr="_connection.CustomUrlParams" value="FromDate=[_input.from]&ToDate=[_input.to]" />
<api:script method="GET">
<api:check attr="_input.from">
<api:set attr="URI" value="https://<rest url>/api/Collection"/>
</api:check>
<api:call op="jsonproviderGet">
<api:push/>
</api:call>
</api:script>
And custom url parameters can also be mixed with pagination as well.
Parameters and pagination
This is an old method I used before learning the nesting metods explained above, it works if it is only an single level you go down, but can't do more than one. I would suggest to use the nesting method.
We will do something different in the file besides using pagination. We are going to add an id field from an rsd file called posts as an parameter in the rsd file comments. The two files mentioned are not added as links as they are not from an free to use source.
Below is how to set up the post id as an input field.
<input name="rows@next" default=1 desc="Identifier for the next page of results. Do not set this value manually."/>
<input name="PostId" xs:type="string" other:filter="{PostId}" default="111"/>
</api:info>
<api:set attr="DataModel" value="DOCUMENT" />
<api:set attr="BaseURI" value="https://timextender.zendesk.com/api/v2/community/posts/{PostId}/comments.json" />
<api:set attr="RepeatElement" value="/json/comments" />
We add an input field as explained in the Use Parameters section. The difference is that it is utilized in the BaseURI value in an {} area, not as an [_input.postid] and that it is has set an other:filter="{input name}".
To see the comments table you will have to add a custom data selection rule that looks like so.
[PostId] IN (SELECT [id] FROM REST.Posts)
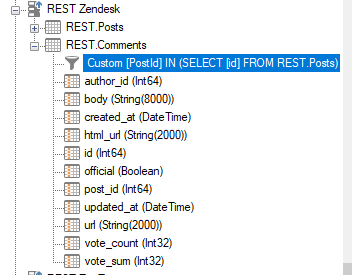
This will make the Comments table iterate over each PostId that gets added to the IN statement.
You can see how this happens if you add a log to the setup. It will show the query in that.
Create an dynamic date range filter
Here is how you set up a dynamic date range.
Is the 'date' value in your script output from the first call to jsonproviderGet? Or are you trying to just get today's date? If this an output from the first call, you could just use the following value to format the returned date to the appropriate format:
<api:set attr="from" value="[date | todate('yyyy-MM-dd')]"/>
If you just want to output today's date, you can use a dummy attribute to call the 'date' formatter like so:
<api:set attr="from" value="[dummy | date('yyyy-MM-dd')]"/>
For values like 'yesterday', you can make use to the dateadd formatter to add or subtract days and then call todate() to format the output:
<api:set attr="from" value="[dummy | date() | dateadd('day', '-1') | todate('yyyy-MM-dd')]"/>
So with this you can make it have a range from first of month, by changing day to month and you can do the same for to. If you want it to look way into the future change it yo year instead.
How to use it in an RSD file I have an example below.
I have an uri that can have an start and end date set to filter the data and I set it up like so.
<api:set attr="URITemplate" value="https://server.name.plus/test/api/node/12345/realized-hours/{from}/{to}" />
The uri I use is the nested part and I have added an {from} and {to} parameter to it.
To set this up in the call I do the following.
<api:script method="GET">
<api:set attr="method" value="GET"/>
<api:set attr="from" value="[dummy | date() | dateadd('day', '-1') | todate('yyyy-MM-dd')]"/>
<api:set attr="to" value="[dummy | date() | dateadd('day', '+1') | todate('yyyy-MM-dd')]"/>
<api:set attr="URI" value="[URITemplate | replace('{from}', [nodeout.from]) | replace('{to}', [nodeout.to])]"/>
<api:call op="jsonproviderGet">
<api:push/>
</api:call>
</api:script>
So I set from to be today -1 and to be today +1 and this will give me only the data from the last two days.
This can then be used in conjunction with incremental load to decrease the number of rows the program is going through. The only necessity is that the API has the option to filter by date. Additionally, there is some more info about this in the link added to the first section.
Links and files
All the RSD files I have used in these are added as attachments and here is a list of connection strings for the various parts. They can be copied into a connection string field in a REST CData provider and work with very little customization.
GoREST connection string: location=S:\Shared\TestData\FlatFiles\GoREST;logfile=S:\Shared\TestData\FlatFiles\GoREST\log.txt;row scan depth=0;verbosity=2
Change the location and log folders and store all the files attached there to set it up
Fixer.IO connection string: generate schema files=OnUse;location=S:\Shared\TestData\FlatFiles\Fixer;uri="http://data.fixer.io/api/2020-01-20?access_key=522b683569a91b66be6be214027b47bf"
Add the fixer file to a folder and you should have access.
I haven't added it here, but try to set up pagination for REQES, I chose GoREST because it had nested resources, but you can still use it for most of the other things.



3 Comments