Overview
This guide will cover connecting TimeXtender to data sources in Azure Data Lake Storage Gen2, as there are multiple ways to connect. We'll compare 6 ways to connect to ADLS data.
- Methods for Connecting TimeXtender to Azure Data Lake
- Prerequisites
- File Types and Data
- Benchmarking - Speed to Write Data to ADLS Gen2 with TimeXtender
- Discussion
1. Methods for Connecting TimeXtender to Azure Data Lake
There are four different data provider used in this experiment, but 6 configurations as ADF can be used for CSV, Avro, or Parquet file, which show varying performance.
The Azure Data Factory (ADF) data providers are included by TimeXtender directly (not from CData).
The following link will walk you through how to Use Azure Data Factory for Data Movement (with TimeXtender), which includes ingestion (source to ODX) and transport (ODX to MDW).
For the CData connectors, a third party delivering ADO.NET data providers featured in the TimeXtender platform, please see their Knowledge Base containing detailed connection information including Establishing a Connection, Data Model, and Connection String Options.
CData ADO.NET Provider for CSV
CData ADO.NET Provider for Parquet
CData ADO.NET Provider for Azure Data Lake Storage
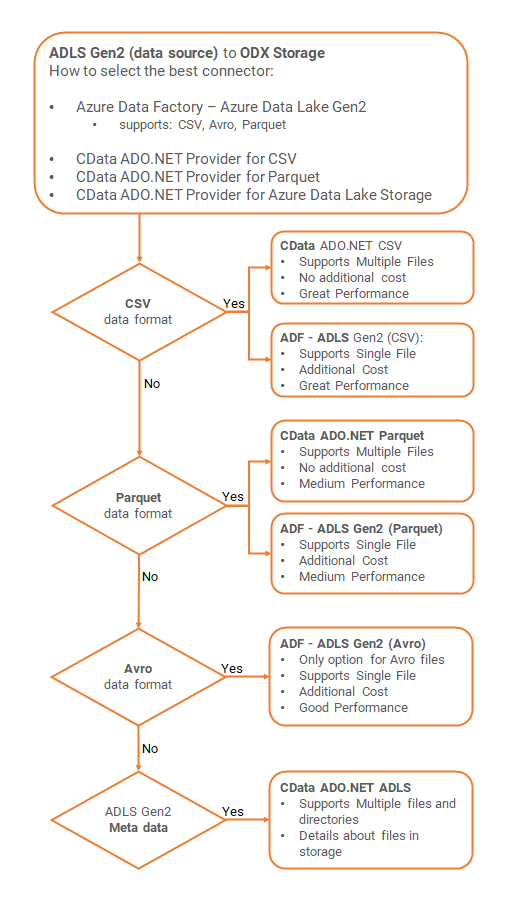
Let the following flow chart be a cheat sheet how to best connect to Azure Data Lake Storage. Starting fromt the top of the flow chart, follow the questions to reveal your best options to connect your data source to the ODX Storage. After the flow chart, we'll compare performance using the various connector options to add more understanding on your best options,
2. Prerequisites
To run this example, we have already loaded our data into an Azure Data Lake. We have also created an Azure Data Factory and Service Principle for testing. as well. For more information how to set up these Azure Services, please see the following articles in the Knowledge Base.
Use Azure Data Factory for Data Movement
Additionally, I have a working TimeXtender, environment in an Azure VM, though I really only use the ODX Server for this testing. Here is a basic reference architecture of the testing setup.
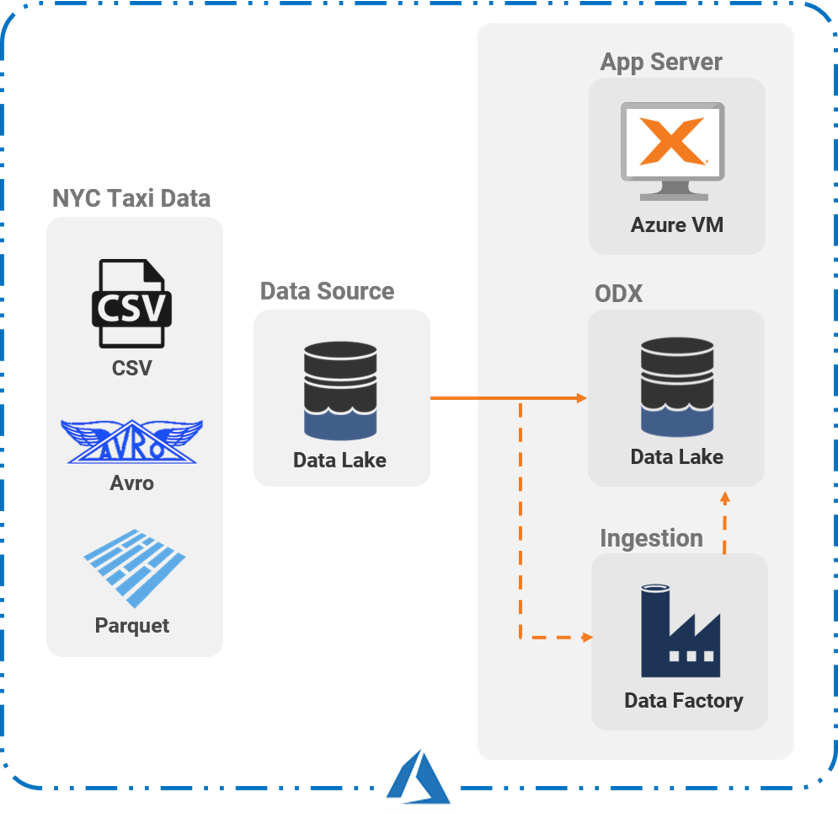
Using two ADLS Gen2 accounts, one ADF, and one TimeXtender ODX, I tested three types of files to see which connectors performed best.
3. File Types and Data
Using the same data, we'll compare the speed to write data to the ODX Storage from ADLS Gen2 in three different file formats, CSV, Avro, and Parquet.
|
File Type |
Description |
Pros |
Cons |
|
CSV (1972)
|
CSV is a row-based data storage, which is essentially a human-readable, plain text file, delimited by commas. Though CSVs are a very common way to use "small" amounts of tabular data, they simply do not scale very well compared to the other systems. |
|
|
|
Avro (2009)
|
Avro is a row-oriented data storage format that "relies on schemas". As a result, making changes to the schema, adding or removing columns, is much easier than column-oriented storage. Furthermore, Avro is highly optimized for reading a subset of entire rows. |
|
|
|
Parquet (2013)
|
Parquet is a column-oriented data storage format created on the Apache Hadoop ecosystem. Parquet is highly optimized for big data as it is exceedingly small and fast to read a file, especially for a subset of columns altogether. |
|
|



For this comparison, we'll use the NYC Taxi Trip Duration data set, available on Kaggle. The data represents taxi ride trip durations in New York City in 2016, originally published by the NYC Taxi and Limousine Commission. We'll use a subset of the data, about 1.5 million records of data total for each of the different file formats, for comparison.
File Types for Testing Benchmarks - 2016 NYC Taxi Trip Duration data (abridged)
| Data Size |
File Format | Data Storage Format |
File Size |
|
1,458,644 records (10 fields) |
CSV | Row-Oriented | 187.9 MB |
| Avro | Row-Oriented | 122.6 MB | |
| Parquet | Column-Oriented | 49.8 MB |
4. Benchmarking - Speed to Write Data to ADLS Gen2 with TimeXtender
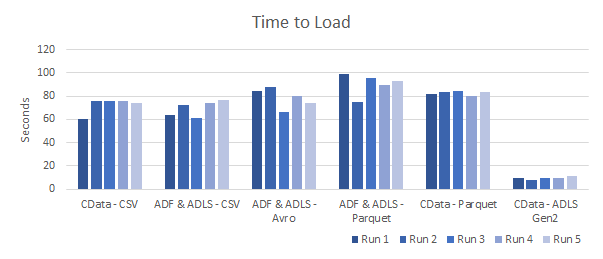
CSV is the fastest file format to get data from the data lake into ODX, all else being equal.
- 1st Place – (60.0 sec) – CData CSV
- 2nd Place – (+ 01.34 sec) – ADF & ADLS (CSV)
- 3rd Place – (+ 06.41 sec) – ADF & ADLS (Avro)
- 4th Place – (+ 14.83 sec) – ADF & ADLS (Parquet)
- 5th Place – (+ 19.84 sec) – CData Parquet
- 6th Place – (Disqualified) – CData ADLS

5. Discussion
It may seem surprising that CSV, regardless of ADF usage, is the fastest file to load from ADLS. Digging into why this is, may need to be another article. It should be noted that the fastest single load time observed used the CData CSV data provider, though the fastest average load time was seen with the ADF data provider and CSV files.
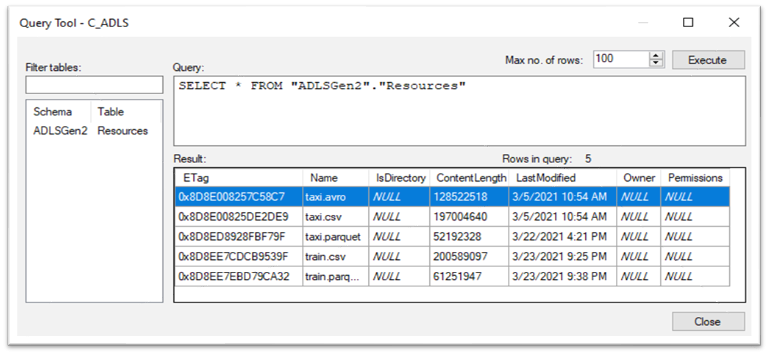
CData Azure Data Lake Storage yields meta data about the data lake, which in not the goal of this performance comparison. Said differently, the CData ADLS connector only loads the meta-data of the data lake, it isn't an "apples to apples" comparison. This also explains the sub-10 second time to load. But, you may think of times that you'd want to include this information in your data solution, as this connector can grant automation to the state of the data lake, unlike any of the other data providers.
0 Comments