Making use of the ODX data, which now uses Parquet file format, can be accomplished by querying your ADLS Gen2 storage with SSMS. Once created and connected, querying the files in your data lake, is a great way to review, inspect, and query data in an ad hoc queries. Using the extreme performance of the new Azure Synapse Workspace, SQL on-demand is a powerful tool that allows you to connect your Synapse Workspace to Azure Data Lake.
In this article you will learn about:
- ODX Parquet File Structure and Incremental Loads
- Prerequisites
- Query the Data Lake with Synapse Workspace
- Using the FILEPATH function to determine ODX version and batch
- Adding the WHERE clause to filter query result by version
- Troubleshooting
ODX Parquet File Structure and Incremental Loads
Version 20.10 brought many new capabilities and changes to the way the Operational Data Exchange stores and manages data. The most significant of these changes is “The ODX Never Forgets”, meaning that, by default, data is no longer truncated from ODX storage. Instead, new full loads are simply appended to the existing data in storage. While the ODX will automatically handle pulling only the most recent version of data into the data warehouse, this can create some challenges when querying from the ODX Storage directly.
To help with this, the ODX now identifies data in a table by batch and version.
- A batch contains only the rows for a table processed during a single execution.
- A version consists of multiple batches, the initial full load (i.e. Batch 0000), as well as all subsequent incremental loads (i.e. Batches 0001-9999).
When using Azure Data Lake storage, the ODX creates a unique file structure that can be used to determine the most recent version of data. Starting at the Container level, the file structure for a single table may appear as follows:
- <DataSource>
- <Schema_Table>
- DATA_<2020_10_25…> VERSION create date
- DATA
- DATA_0000.parquet Initial full load BATCH
- DATA_0001.parquet Subsequent incremental batch
- DATA_0004.parquet Subsequent incremental batch (batch numbers do not always follow an exact increment.)
- DATA
- DATA_<2020_10_27…> New Version created due to schema drift or manually executed full load
- DATA
- DATA_0000.paquet the same pattern repeats as above…
- DATA
- DATA_<2020_10_25…> VERSION create date
- <Schema_Table>
Using this file/folder structure we can conclude that each version folder will include ALL rows that the ODX has extracted until the next version is created. So to query the most recent version of data extracted by the ODX in Data Lake, you can just look into the latest VERSION folder. The steps below will guide you through this process using Synapse Workspace SQL On-Demand.
Prerequisites
- Create a Synapse Workspace (MSFT: Create a Synapse Workspace)
- Note: When creating your workspace, make sure to create your own Security credential, rather than the default, sqladminuser.
- Connect SQL Server Management Studio (SSMS) to your workspace (MSFT: Connect Synapse to SSMS)
- Note: When connecting SSMS to your Synapse workspace, make sure to use the "SQL on-demand endpoint, rather than the SQL endpoint.
Query the Data Lake with Synapse Workspace and SSMS
Using a Synapse Workspace to query Parquet files is straightforward. (MSFT: Query Parquet files)
For illustration, we'll use the AdventureWorks2014 database for our query results examples, specifically the Production.Product tables.
- In TimeXtender, Execute a data source in the ODX (connected to your ADLS Gen2 account).
- In Azure Storage Explorer, verify that the data source has been executed.
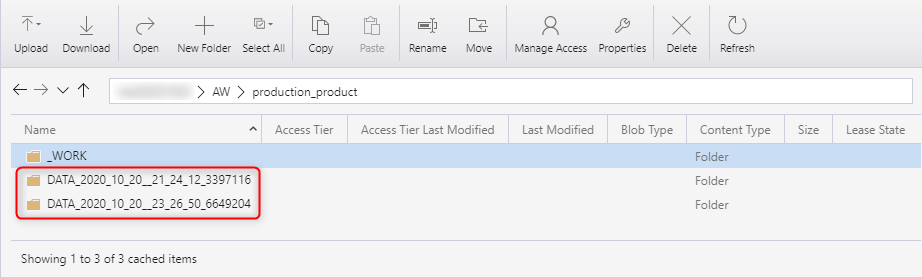
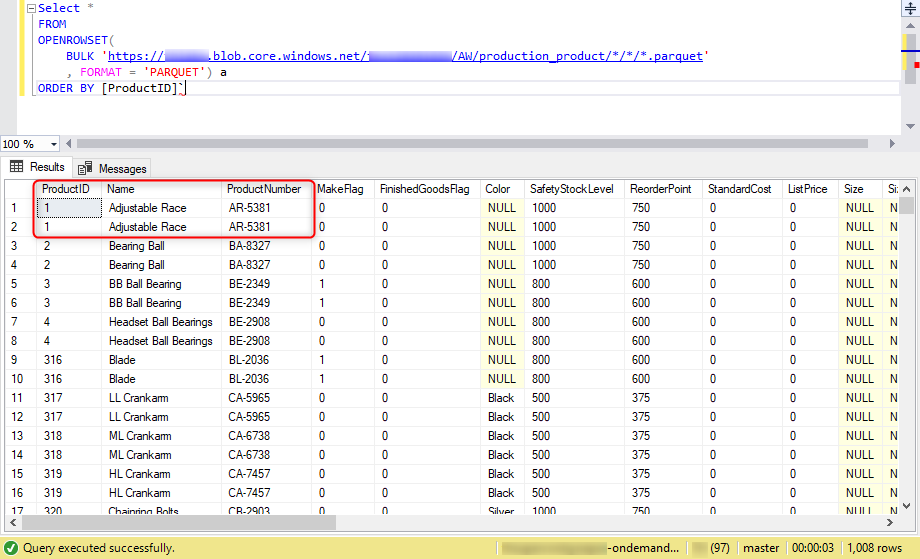
- In SSMS, we'll execute the following query to connect to our files.
-
--Query ODX Parquet files (returns all records)
SELECT *
FROM OPENROWSET(
BULK 'https://<StorageAccountName>.blob.core.windows.net/<ContainerName>/<DataSourceShortName>/<Schema_TableName>/*/*/*.parquet'
, FORMAT = 'PARQUET') AS a- Note: you must alias the OPENROWSET, or you'll likely receive the error message, "A correlation name must be specified for the bulk rowset in the from clause."
- Wildcards, using the * symbol, can be used in the file path
- StorageAccountName is the name of the ADLS Gen2 account
- ContainerName is the target storage container
- DataSourceShortName is the short name of the data source, as defined in the ODX
- Schema_TableName is the data source schema and table name
-
- Upon execution, you'll notice we are able to see that we're able to run generic SQL directly onto data in the data lake.
Using the FILEPATH function to determine ODX version and batch
- The ODX data sources won't include an ODX_Timestamp within the table, (as of TimeXtender 20.10.1), but the filepath actually does contain the timestamp information. We can use the file path to identify the data timestamps.
- The filepath function can greatly simplify how we'll extract the entire filepath string, or sections of it. To get the entire filepath, we can use the filepath function with no arguments inside the parentheses.
-
--Get the complete filepath
a.filepath() AS [FilePath]
-
- Next, we can provide an argument to extract the first wildcard from the full filepath, which is the ODX_Version. For example, filepath(1) will return the string represented by the first instance of a wilcard
-
--Extract the date/time part of the file path
a.filepath(1) AS [ODX_Version]
-
- Lastly, we can provide an argument to extract the first wildcard from the full filepath, which is the ODX_batch. For example, filepath(3) will return the string represented by the first instance of a wilcard
-
--Convert the parts of the date/time path to a DateTime data type
a.filepath(3) AS [ODX_batch]
-
- We can further simplify the filepath wildcard string results by adding "DATA_" before the wildcard symbol in the openrowset function filepath string. For example, "/DATA_*/" will not include "DATA_" in results, but only the characters after it.
-
FROM OPENROWSET(
BULK 'https://<StorageAccountName>.blob.core.windows.net/<ContainerName>/<DataSourceShortName>/<Schema_TableName>/DATA_*/*/DATA_*.parquet'
, FORMAT = 'PARQUET') AS a
-
- Putting the whole thing together would look like the following. We'll add three columns to our query result to help clarify the timestamps, FilePath, ODX_Version, and ODX_Batch.
-
--Query ODX parquet files with TimeStamps on rows. (Returns all records)
SELECT
--Get the Filepath (you need to add the table reference or this function will not work)
a.filepath() AS [FilePath]
--Extract the date/time part of the file path
,a.filepath(1) AS [ODX_Version]
--Convert the parts of the date/time path to a DateTime data type
, a.filepath(3) AS [ODX_batch]
,*
FROM OPENROWSET(
BULK 'https://<StorageAccountName>.blob.core.windows.net/<ContainerName>/<DataSourceShortName>/<Schema_TableName>/DATA_*/*/DATA_*.parquet'
, FORMAT = 'PARQUET') AS a - NOTE: Above you must alias the OPENROWSET, and be sure to use the same alias in the references above.
-
- The query result is much easier to understand, but we still have duplicate records.
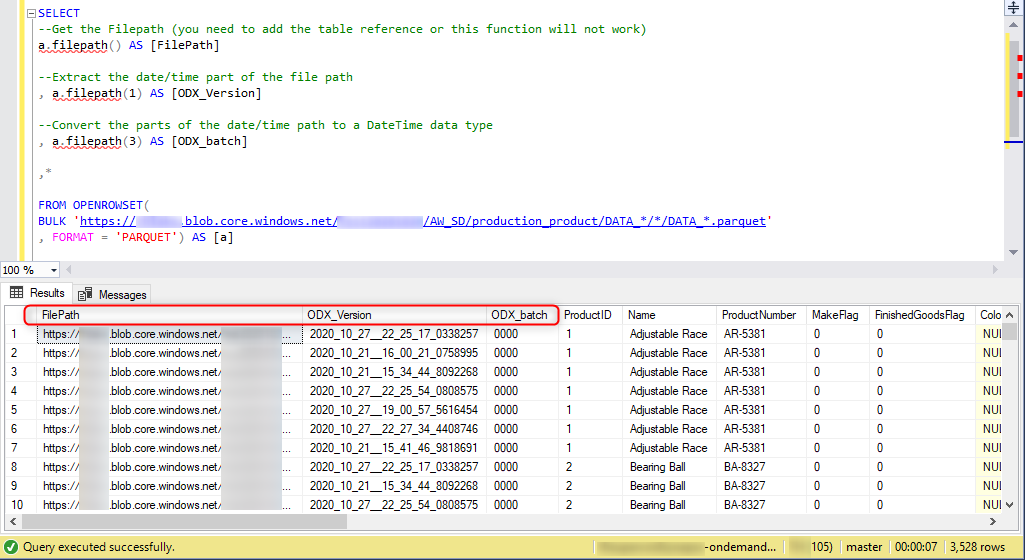
Adding the WHERE clause to filter query result by version
- Now, to only select the most current data load, we'll add a sub-query WHERE clause.
-
WHERE a.filepath(1) = (
SELECT MAX(a.filepath(1))
FROM OPENROWSET(
BULK 'https://<StorageAccountName>.blob.core.windows.net/<ContainerName>/<DataSourceShortName>/<Schema_TableName>/DATA_*/*/DATA_*.parquet'
, FORMAT = 'PARQUET'
) AS rows
-
- Putting it together, we can use the following query.
-
--Query and filter ODX Parquet files with TimeStamps on rows. (Returns only latest records)
SELECT
--Get the Filepath (you need to add the table reference or this function will not work)
a.filepath() AS [FilePath]
--Extract the date/time part of the file path
,a.filepath(1) AS [ODX_Version]
--Convert the parts of the date/time path to a DateTime data type
, a.filepath(3) AS [ODX_batch]
,*
FROM OPENROWSET(
BULK 'https://<StorageAccountName>.blob.core.windows.net/<ContainerName>/<DataSourceShortName>/<Schema_TableName>/DATA_*/*/DATA_*.parquet'
, FORMAT = 'PARQUET') AS rows
WHERE a.filepath(1) = (
SELECT MAX(a.filepath(1))
FROM OPENROWSET(
BULK 'https://<StorageAccountName>.blob.core.windows.net/<ContainerName>/<DataSourceShortName>/<Schema_TableName>/DATA_*/*/DATA_*.parquet'
, FORMAT = 'PARQUET'
) AS rows ) - NOTE: Above you must alias the OPENROWSET, and be sure to use the same alias in the references above.
-
- Voila! With this latest query, we can see that our results are now only including the latest data loaded into the ODX.
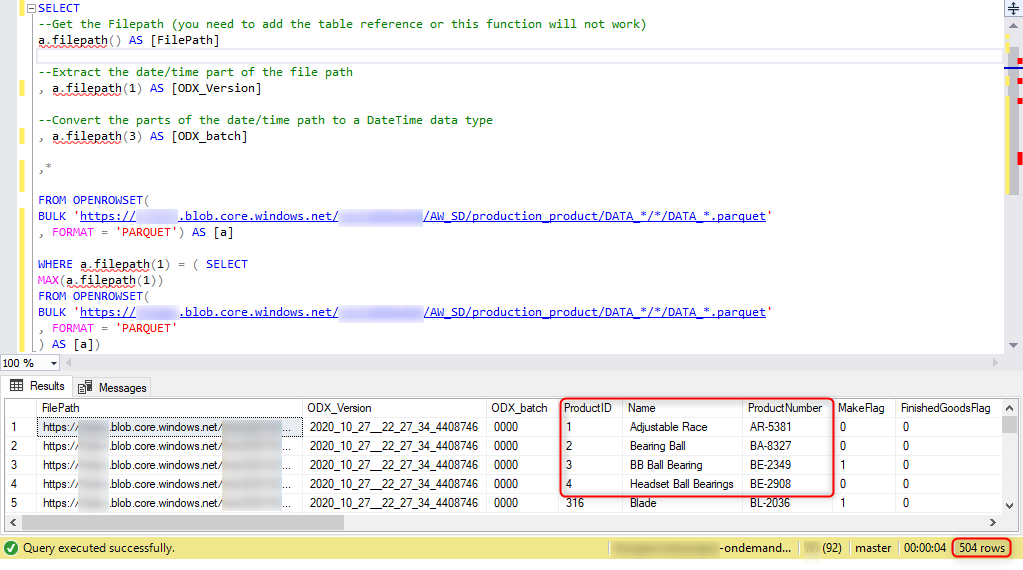
Troubleshooting
- Error message in SSMS, "Incorrect Syntax near Format"
- Ensure you are using the SQL on-demand endpoint, to connect SSMS to your Synapse Workspace. If you re-connect to your Synapse workspace, you may need to create a new query to point to the SQL on-demand endpoint.
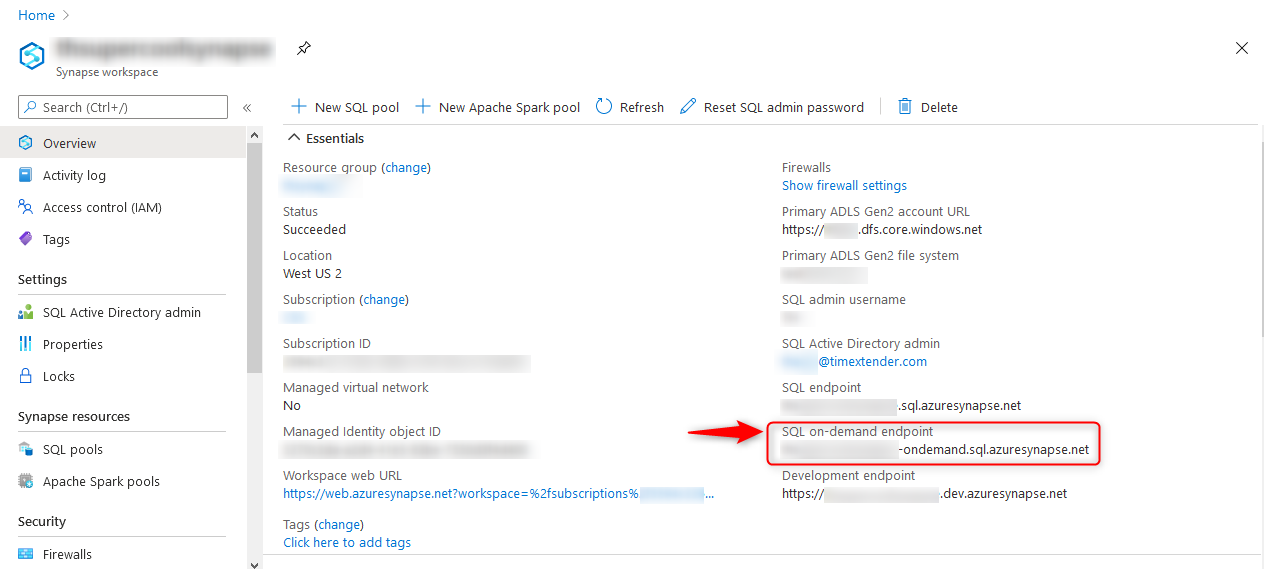
- If your login to the Synapse Workspace (from SSMS) is sqladminuser, you may try either changing the login credentials (i.e. username and password), or create a new workspace.
- Error message in SSMS, "A correlation name must be specified for the bulk rowset in the from clause.
- Ensure that you have aliased the OPENROWSET clause, and the alias matches throughout the query.
- Error message in TimeXtender, "errorCode": "2200", message": "Failure happened on 'Sink' side."
- The issue may be resolved by installing Java Runtime from https://www.java.com/en/download. (Please see KB article JreNotFound error when using Azure Data Factory Data Source with ODX)



8 Comments