Note: There is an updated version of this article, which applies to the next generation of TimeXtender.
Since the release of TimeXtender version 20.5.1 and again with the 20.10.1, the incremental method has been changed. The incremental rule now gets applied on the mapped table. If you have mapped multiple tables into one DWH table, it will have an individual rule for each. The change from 20.10.1 is in regards to how data is added from the ODX store. Now it is a new table/folder per full load and each load besides that will be added as a batch to that.
For incremental load with updates and/or deletes based on ODX sources, you will need to use updates and/or deletes in the setup, otherwise it will not update the data in the DWH. The same applies for deletes from the Business Unit, if the source is not using deletes the DWH can't use it either. You can read about these in the following guide.
We also have the following guide for how it is set up on the creation level. Incremental load method on data source creation level
DWH method
Each mapped table in an DWH table has an individual incremental load rule instead of an overarching one. It uses the max batch number from the incremental table and the source table, then compares that with the PK table to know if there is updates, if set deletes or new rows.
This means that a DWH table with multiple mapped ODX tables can have one mapped table run an full load, at the same time the other mapped table can run incremental with some deletes, a third having no changes and all at the same time without affecting the other mapped tables.
The incremental table
The _I table have seven fields.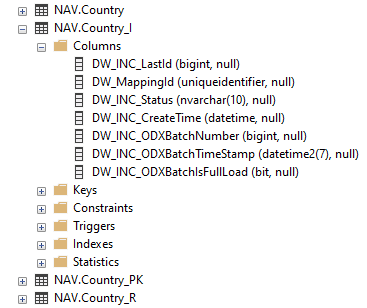
- Last id field
- This is the max DW_Id of the table before the latest execution.
- Mapping id field
- This is the GUID value of the mapping of the two tables. It is used to make sure it always uses the correct table and is stored in the repository.
- Status field
- IF you open a table during execution and goes to the _I table, this will contain an Null value, but after an successful execution it will be set to OK.
- Create time field
- This is the value that is applied as the incremental value have been added for each table.
- ODX Batch Number field
- Is the reference field in the _R table that is used to know what the largest batch is.
- ODX Batch Timestamp field
- Is the date of creation of the latest full load folder or table depending on the store.
- Data Lake
- SQL
- ODX Batch Number Full Load field
- This will show whether an execution was a full load or not.
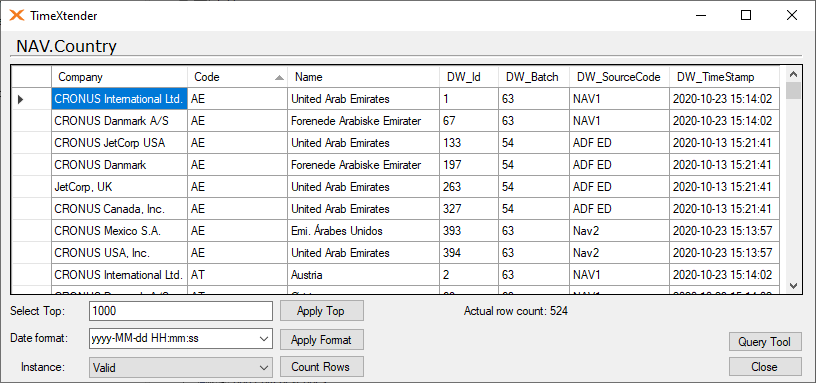
Here is how it looks when two tables are mapped.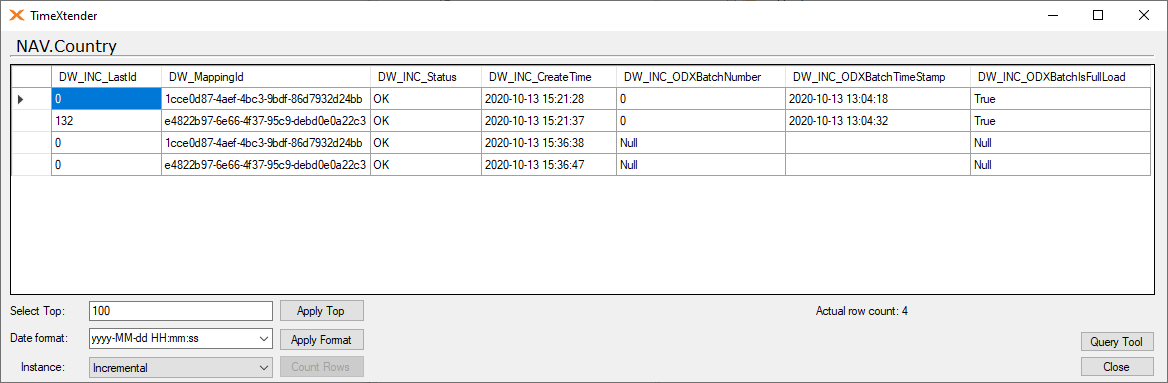
Also what you can see here is that the table have been executed at least twice, but haven't received new data from the source. That is why the ODX fields contain null values.
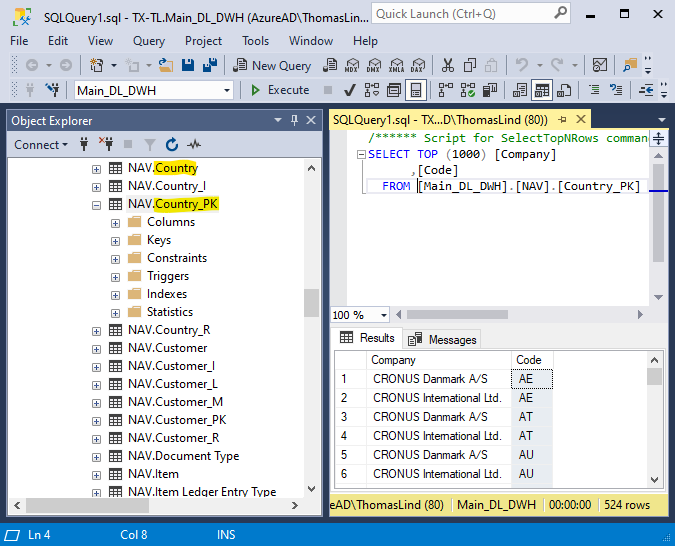
If you want to know the names and ids the DW_MappingId refers to, here is a query based on the repository, that shows you that.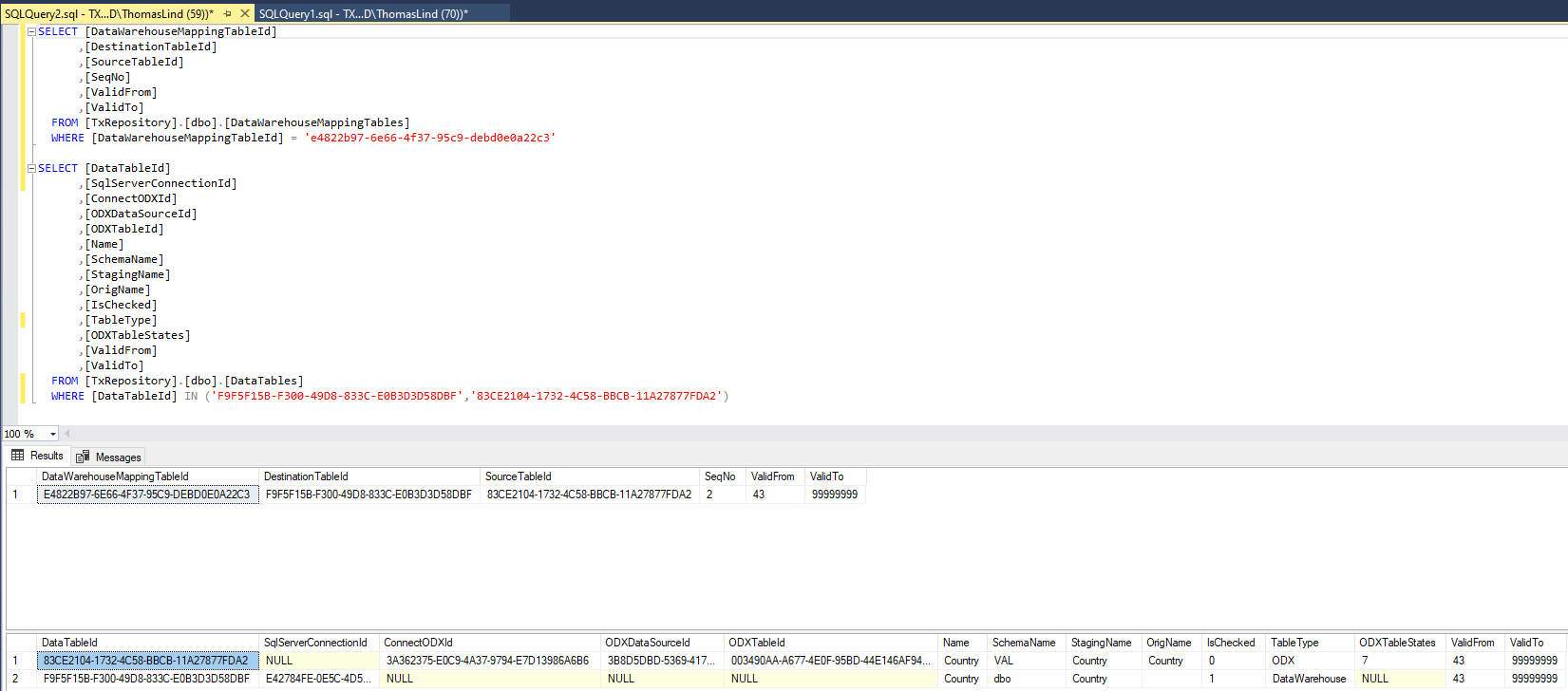
The raw table
There are two fields added, when adding data from an ODX to conform to how the incremental load works.
- ODX Batch Number field
- The reference batch number from the incremental table
- ODX Batch Id field
- The id of the batches. Necessary as you can map more than one table that each have a batch 0 and you would not be able to see the difference otherwise.
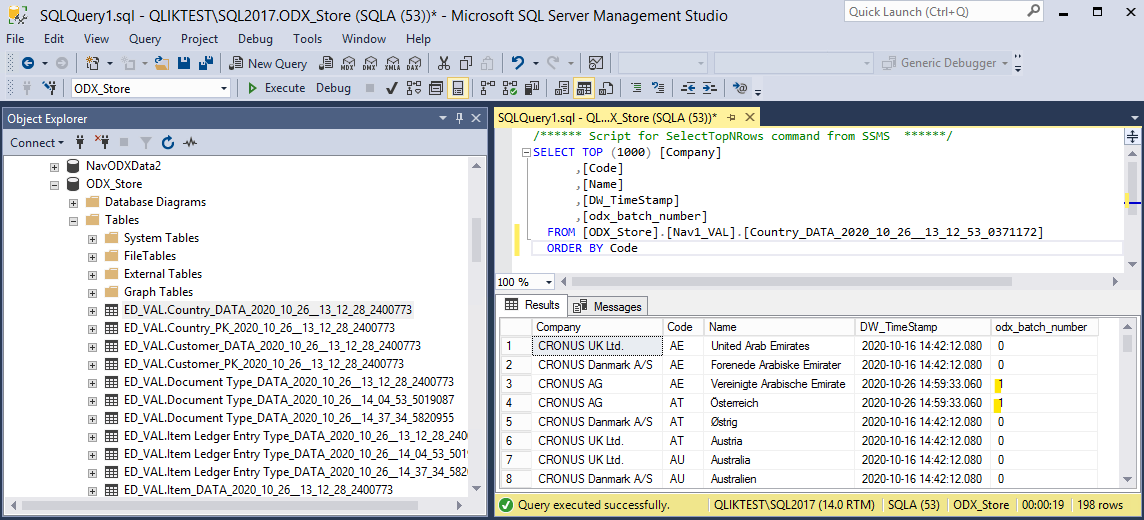
Here is how it looks when there is new data in the raw table.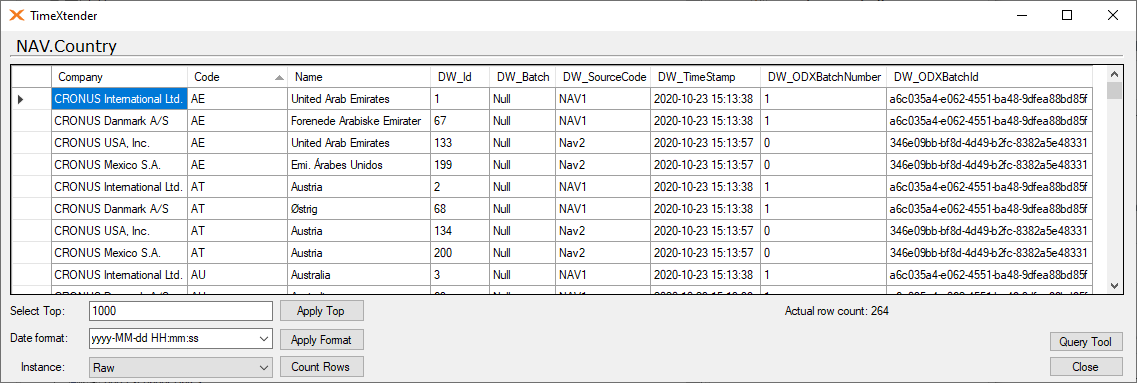
If you relate that to the incremental table, the batch number have in the same numbers.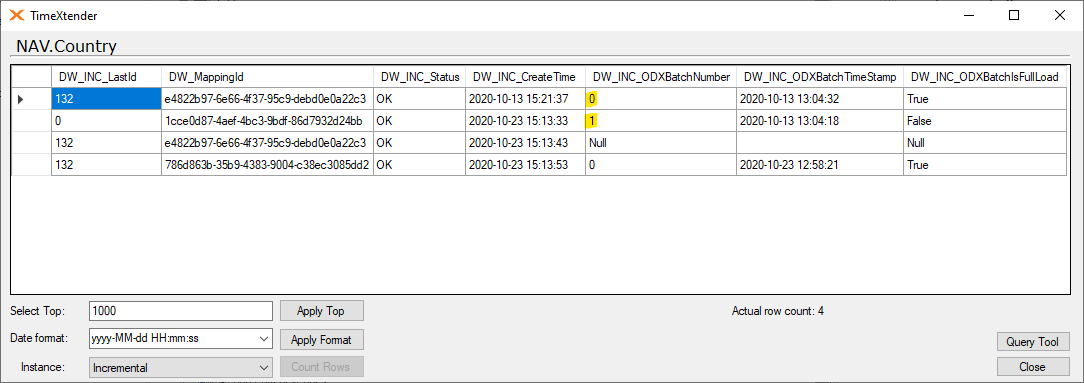
Here is what the reference in the data lake is. Each file has an higher number, which is the Batch number in the other tables.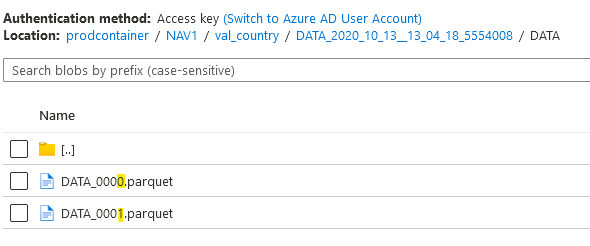
Here is what the reference is in an SQL store. It is an field containing the batch number.
Changes to the valid table
The only change is that since we are not using a specific field in the source to generate an Incremental field, we don't have that. If it was from an BU or another DWH, it would still need to use it.
Deletes
As in the other parts it is also possible to set up deletes on the DWH tables.
It works by comparing the new rows with the primary key and then deleting the row or changing the Is Tombstone field value from False to True.
You can see how this is done in the code by looking at the data cleansing procedure.
Here it is for the Country table using Hard deletes.
-- Incremental load: primary key hard deletes
IF EXISTS
(
SELECT TOP 1 1
FROM [NAV].[Country_I]
)
BEGIN
DELETE V
FROM [NAV].[Country] V
WHERE
NOT EXISTS
(
SELECT TOP 1 1
FROM [NAV].[Country_PK] P
WHERE
P.[Company] = V.[Company]
AND P.[Code] = V.[Code]
)
AND NOT EXISTS
(
SELECT TOP 1 1
FROM [NAV].[Country_R] R
WHERE
R.[Company] = V.[Company]
AND R.[Code] = V.[Code]
)
END
Additionally you can also see how the Updates and Soft Deletes will be applied in there.
Setting up incremental load on tables
We have automated some things, so it isn't necessary to do a lot of setup to use incremental load.
Mapping a table from an ODX source to a DWH table
When you map in a new field from a ODX it will be set as automatic. Depending on what it does in the source, it will be set to do incremental load or not.
Here is how it will look if you map an table using incremental load in the ODX.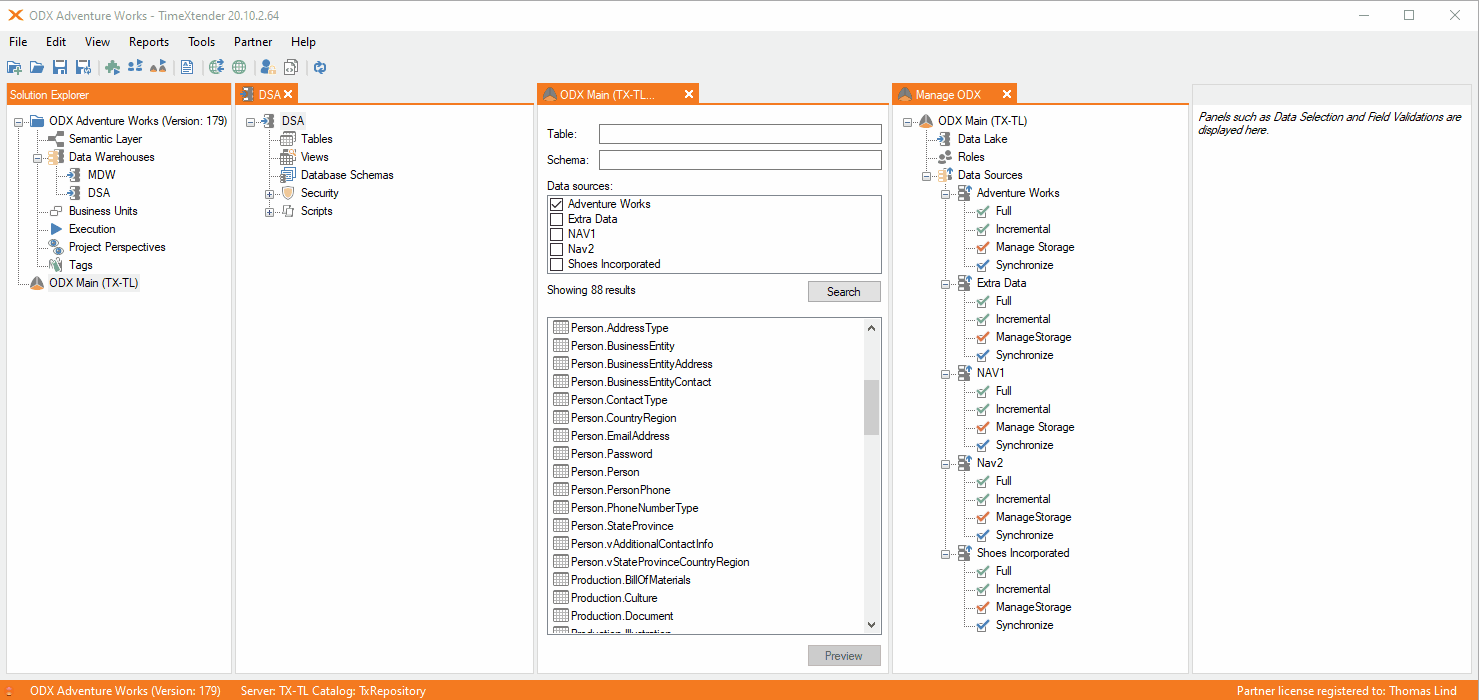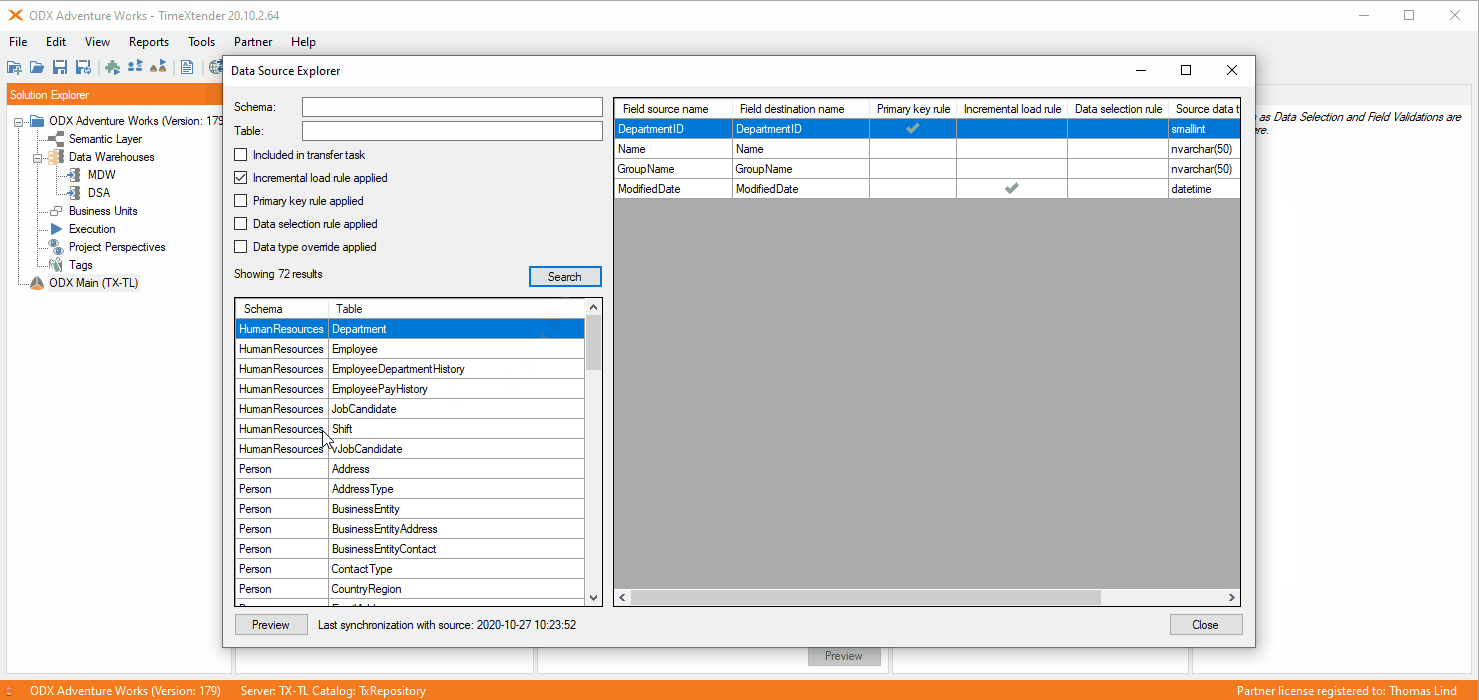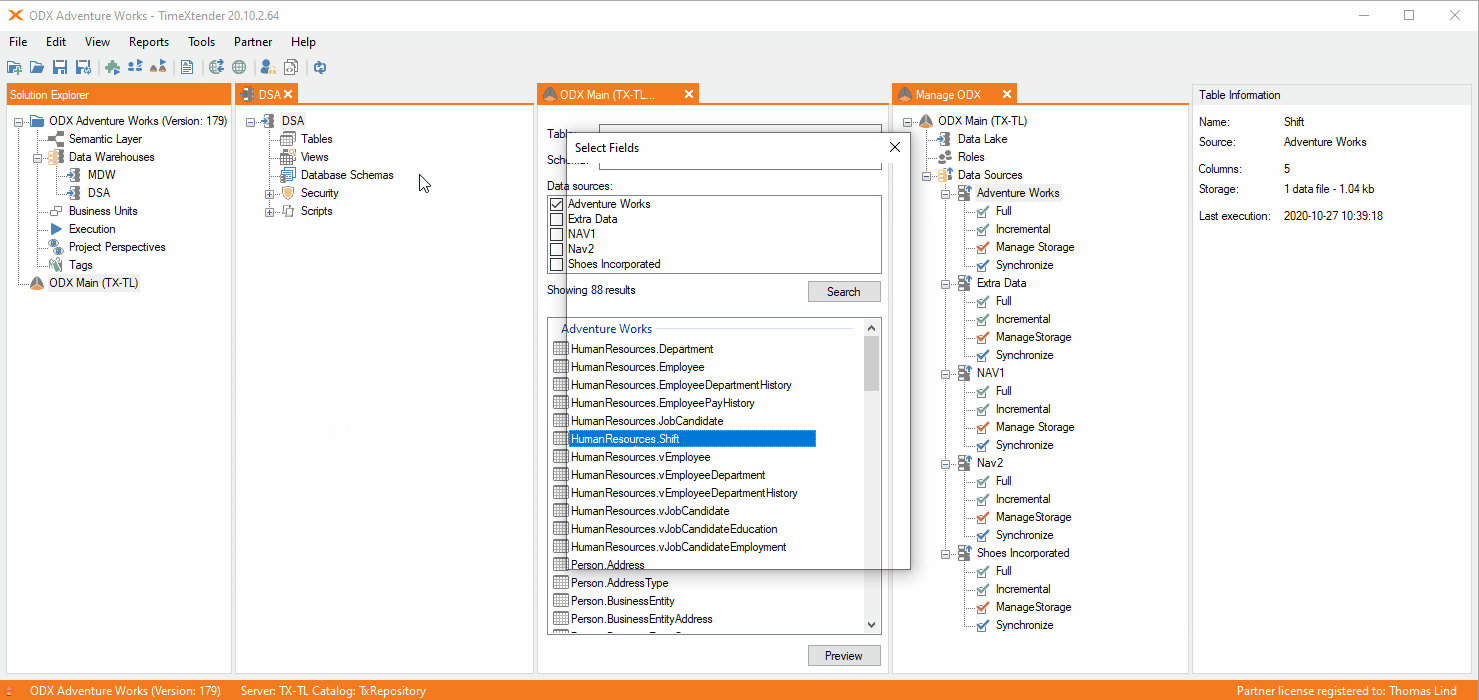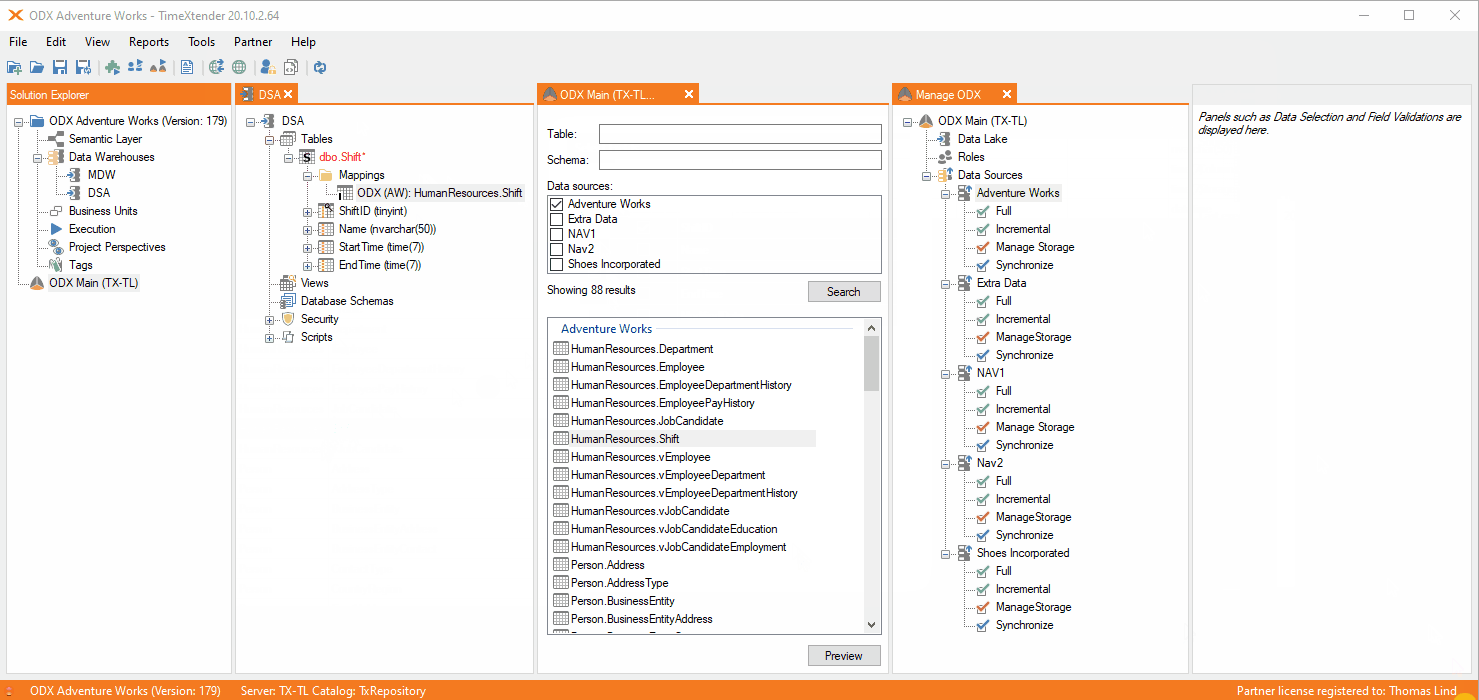
As you can see there is no I icon on the table. Instead you can see that on the mapped table. If you want it to use deletes, you can set it and it will not be required to change the settings to incremental load.
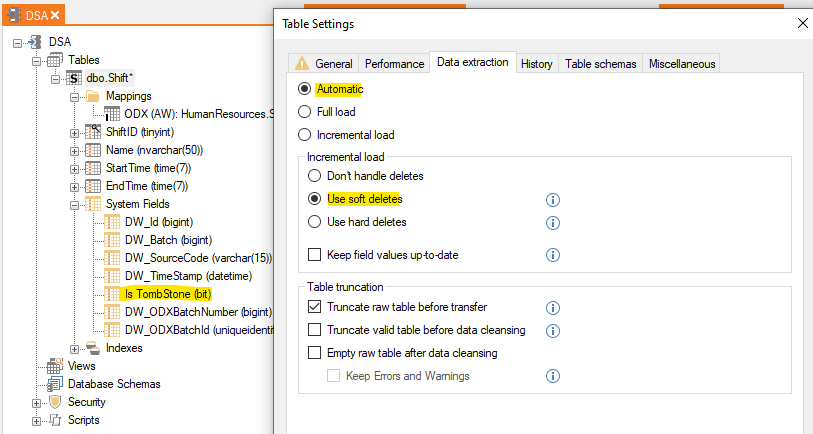
If your table is not running with incremental load in the source it will look like this.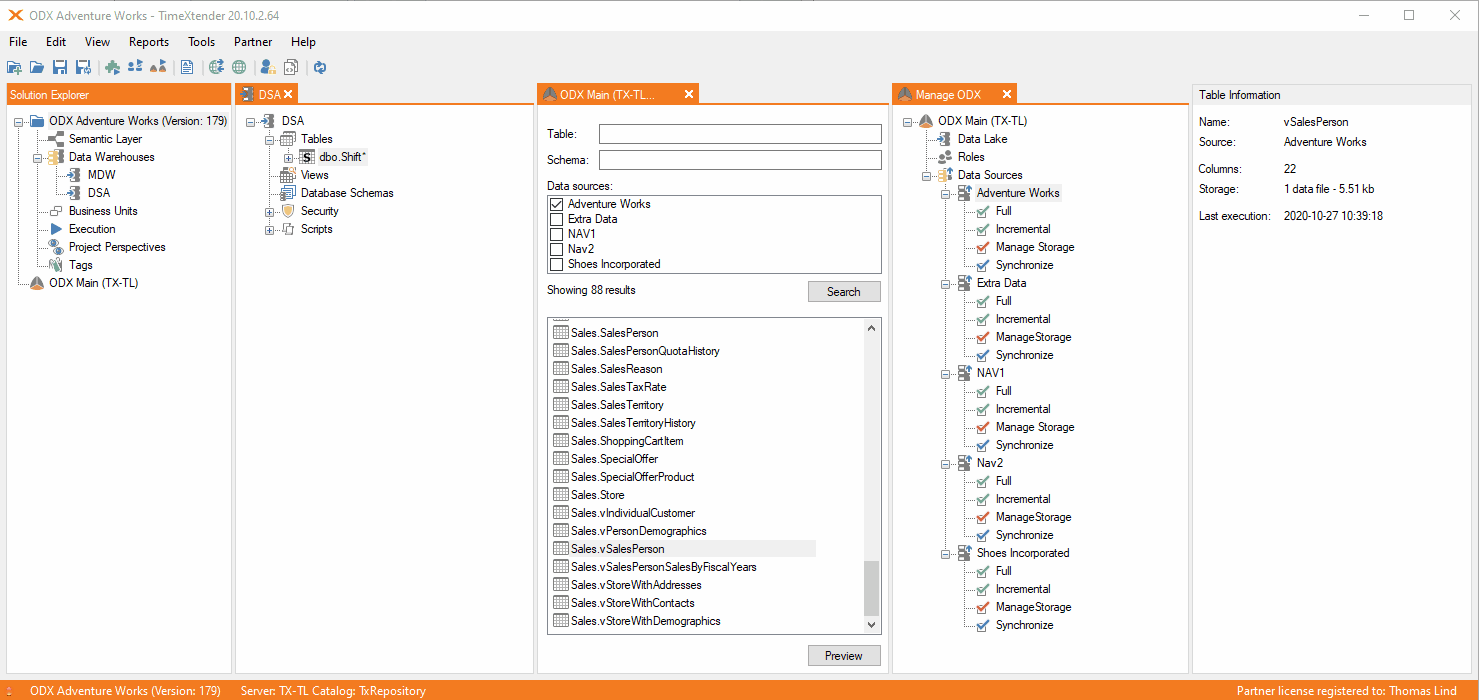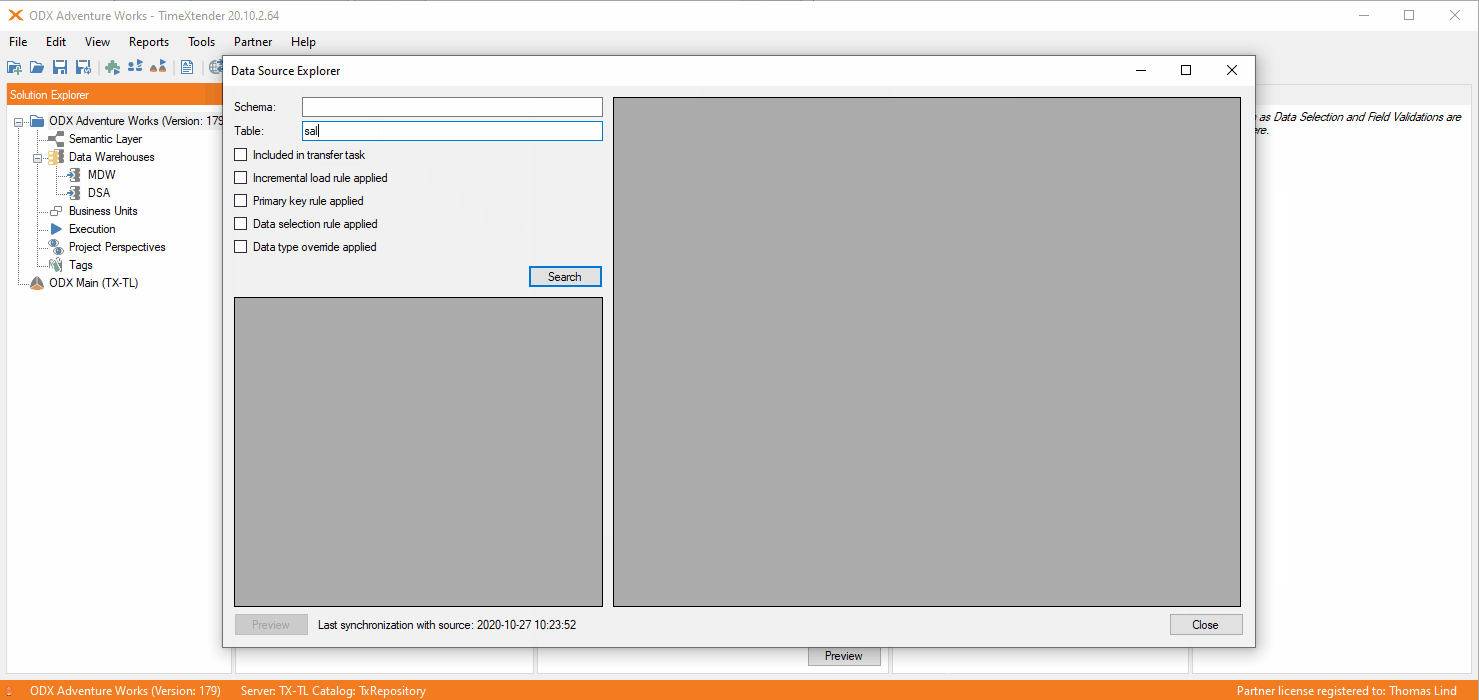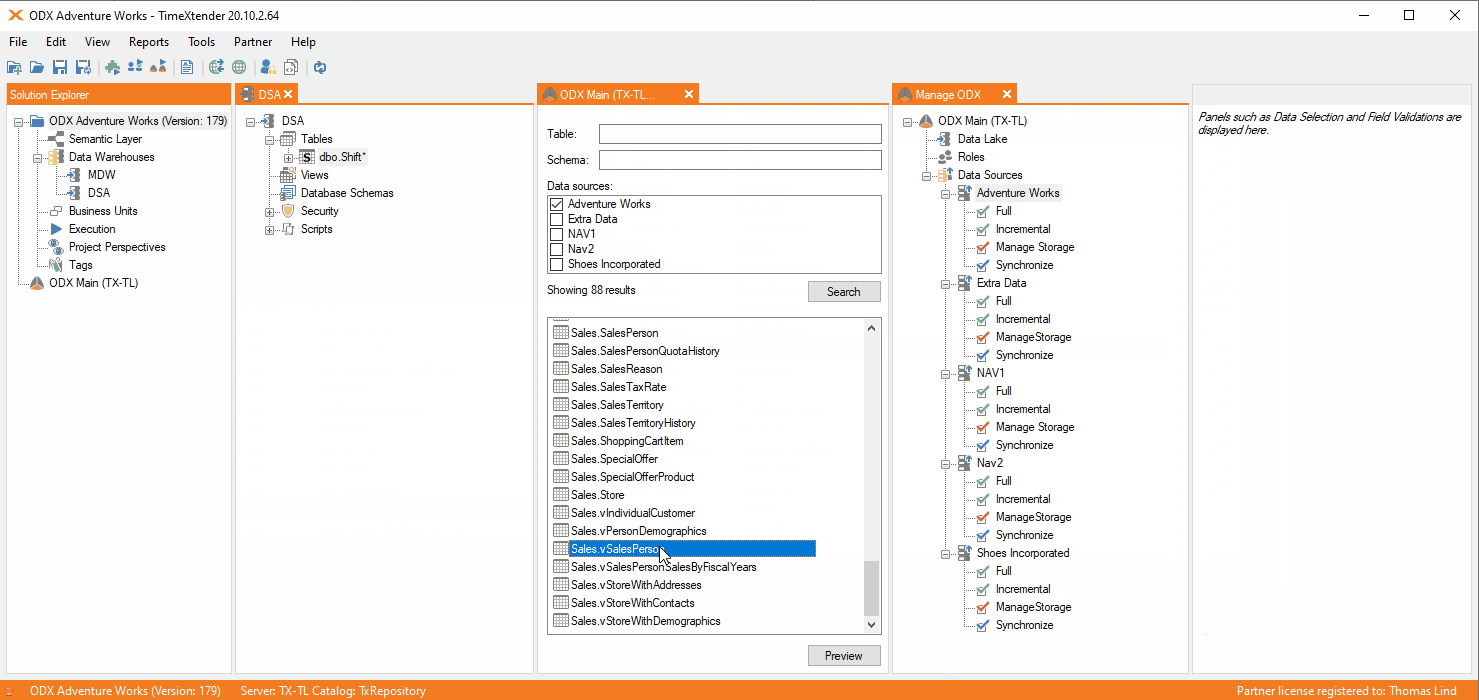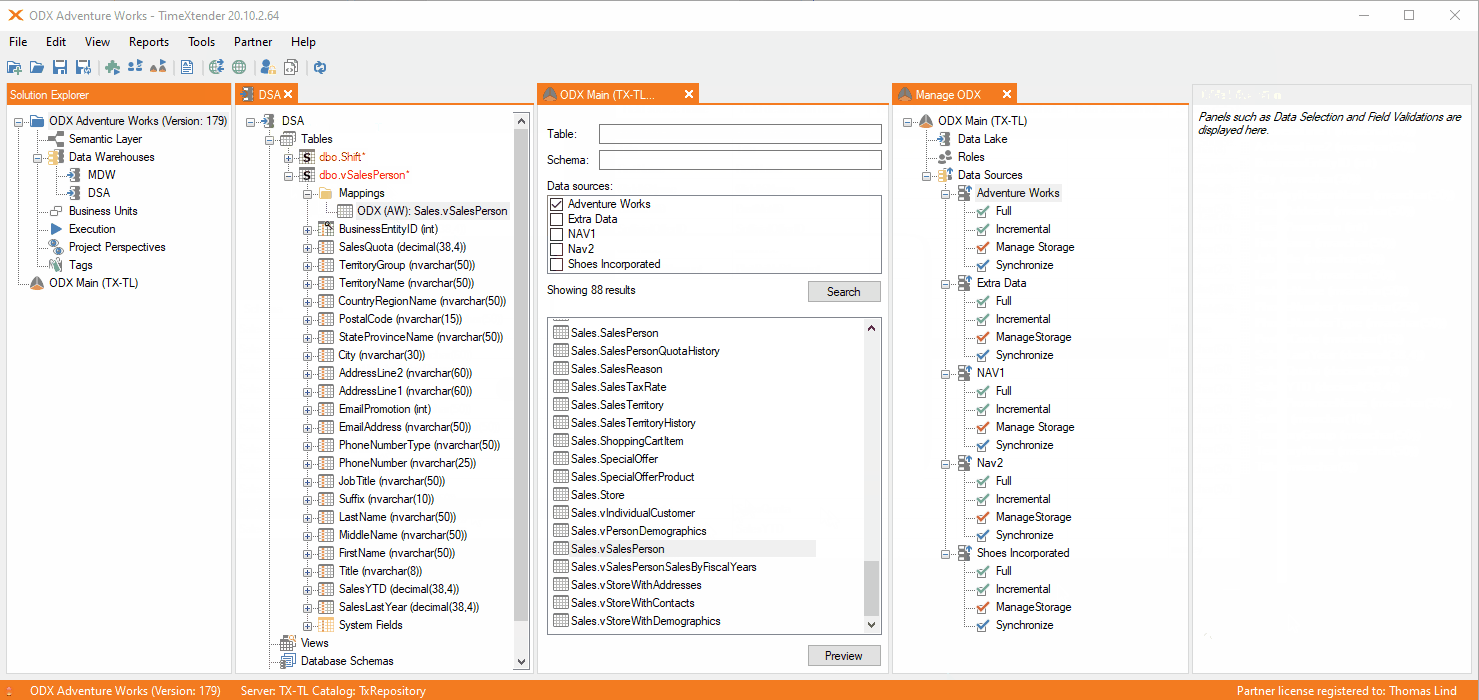
Here there is no I icon on the mapping, but otherwise it is the same. It will still be Automatic and not full load. As the source isn't running incremental load, it will not be required to be changed to full load either.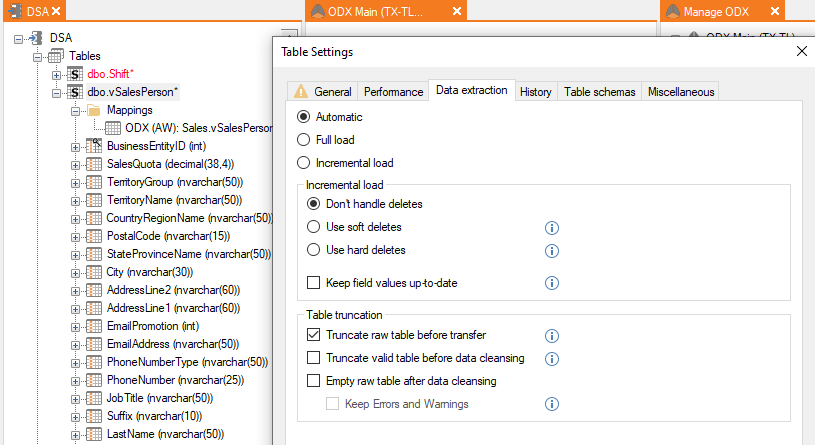
If you want to force an table that is incremental load, to always run with full load, you can control it there, by changing the setting to Full Load. Doing this will gray out the delete handling.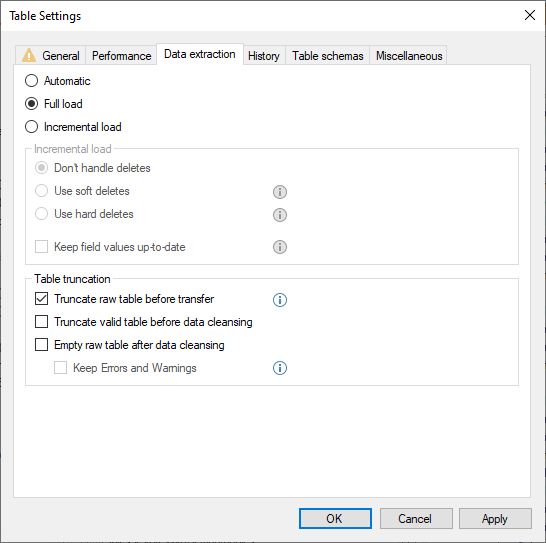
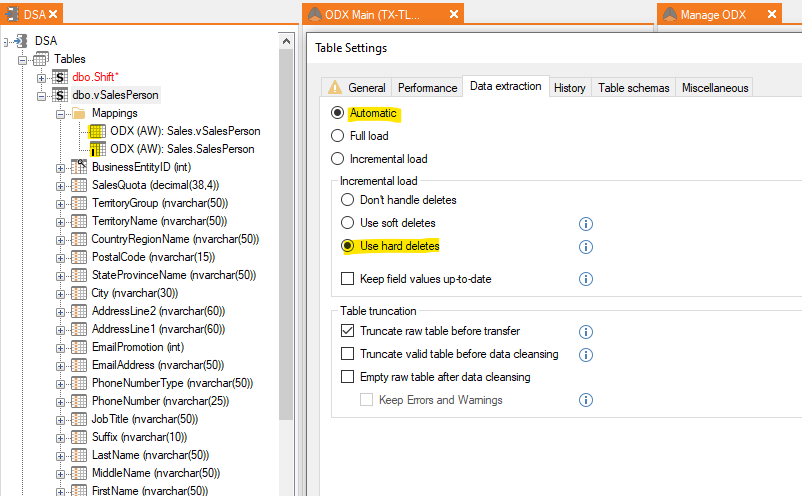
Mapping multiple tables to a DWH table from multiple ODX tables
Incremental rules will be set on the individual mapped table, so you can have one running with and the other without incremental load without any issues. It still doesn't require the setting to be changed from automatic.
Mapping tables from a non ODX source
If you are mapping a table to an table from another DWH it is the same as before. The fastest way for many tables is to use the automate feature.
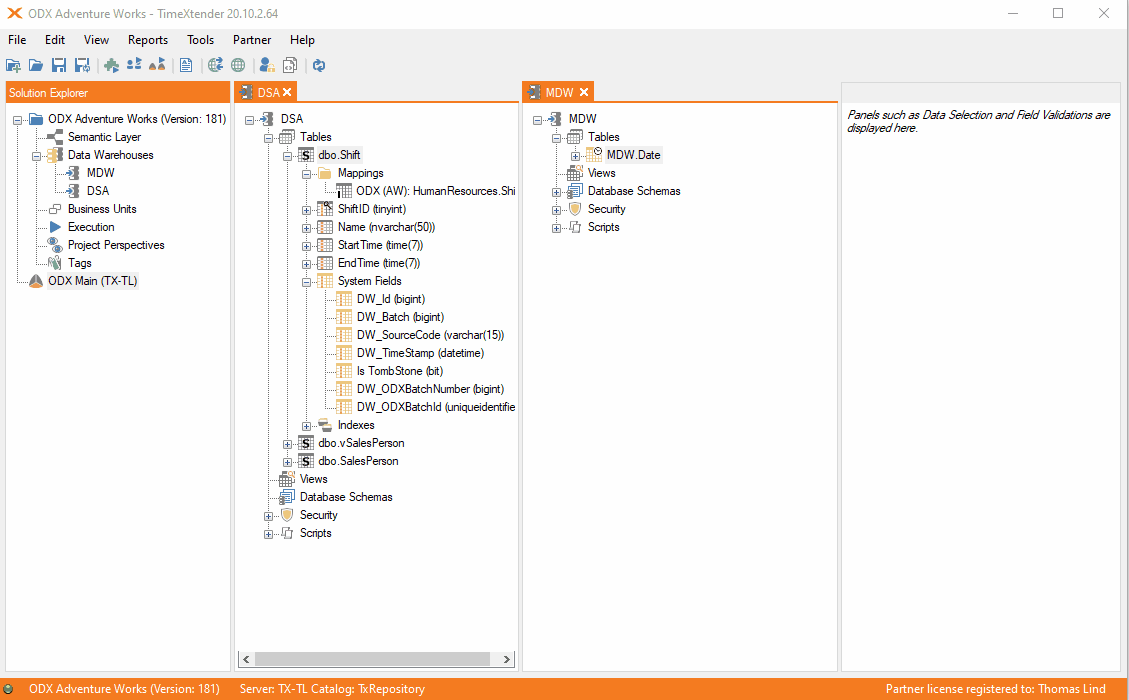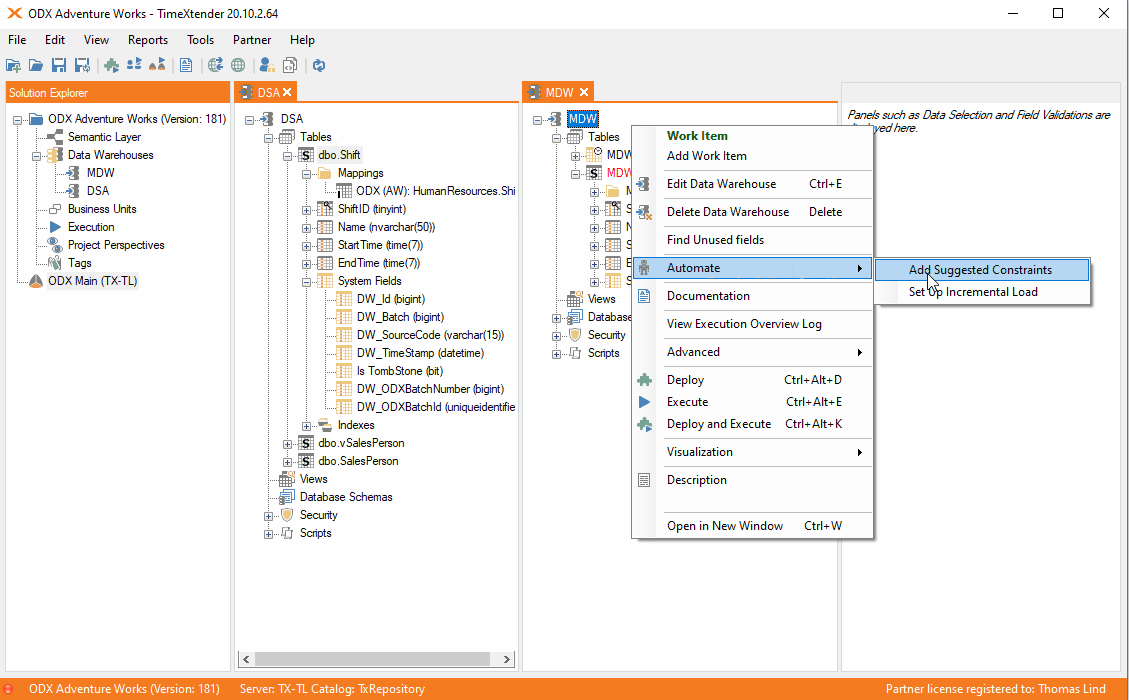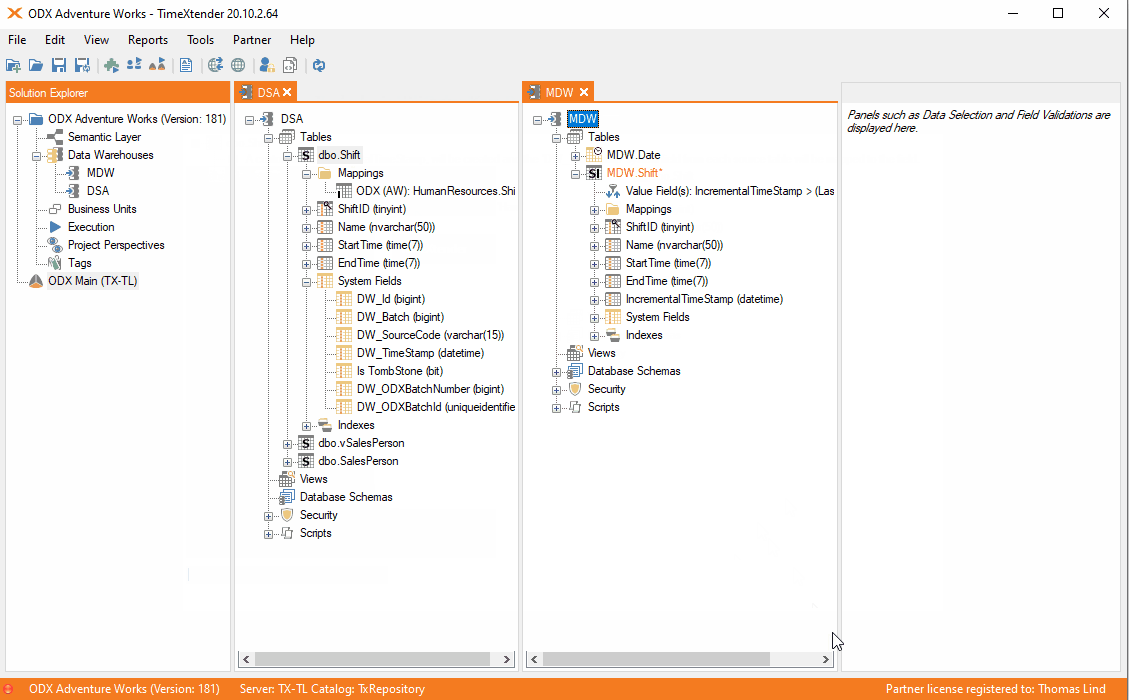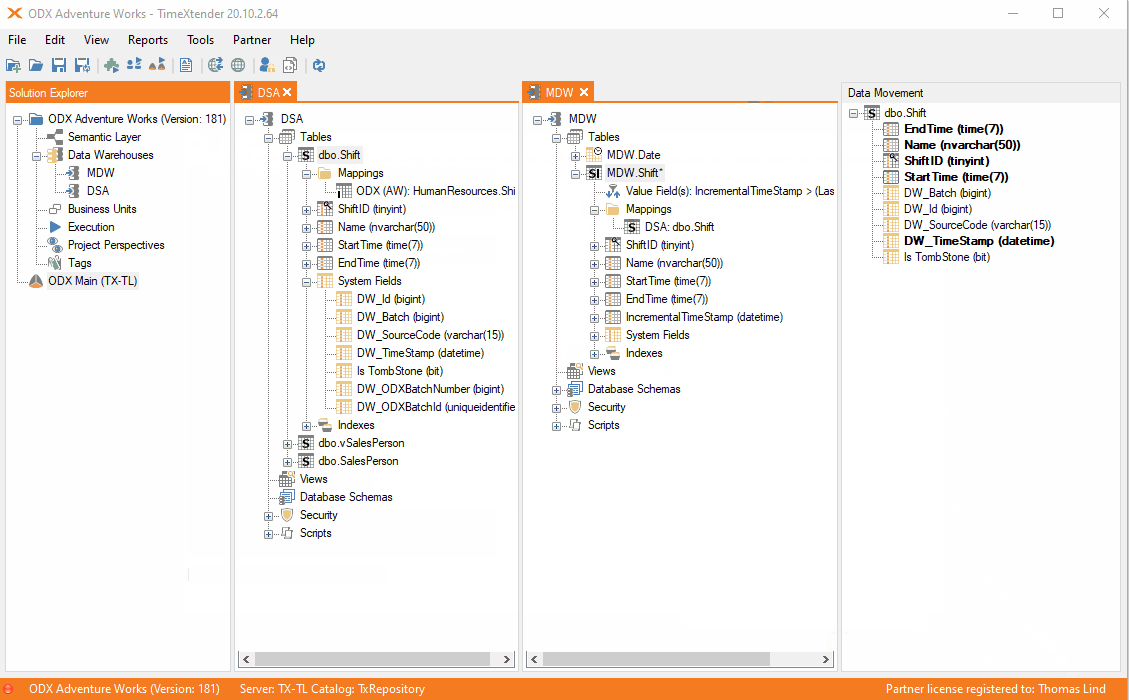
Afterwards the incremental load table will contain the incremental rule.
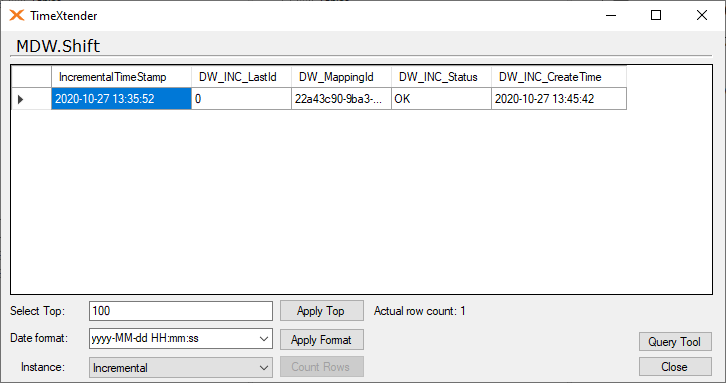
It will require that the data extraction settings are Incremental Load and not Automatic.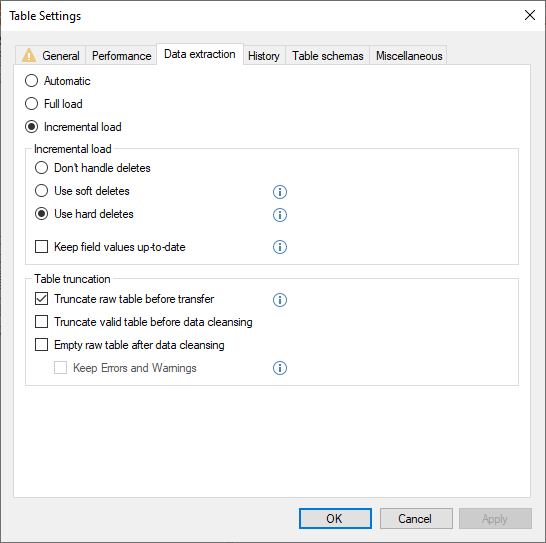
If you are mapping more than one table and and sets up incremental load, it will still create one rule per mapped table.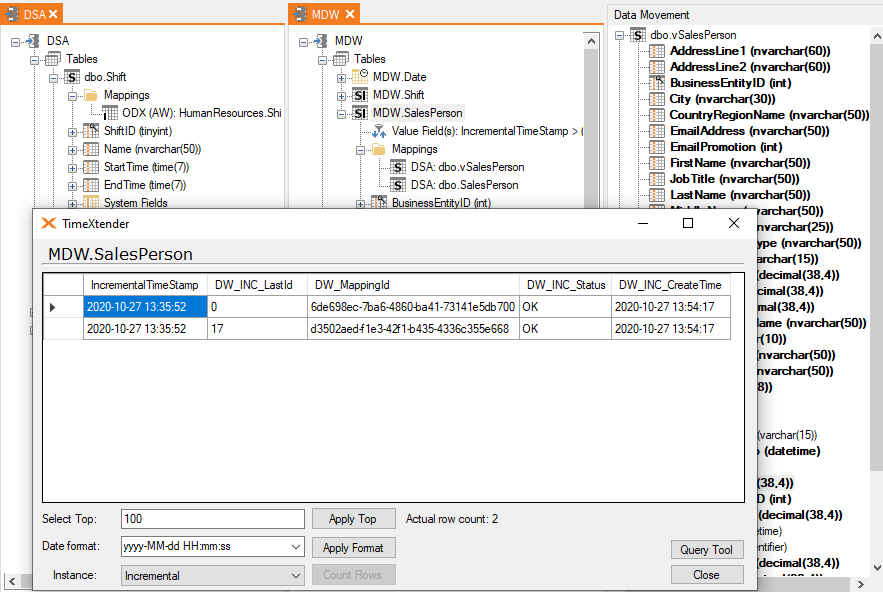
If you map a table from an ODX and another table from another DWH or an BU it will not be possible to use incremental load. One uses the DW_TimeStamp field and the other an ODX Batch number and those two wont mix. You will have to split them out into two tables and then merge them at another point.
0 Comments