When backloading very large tables it may become necessary to load a table in smaller segments or "chunks". The following instructions explain how you can configure a segmented table execution in TimeXtender using a combination of project variables, data selection rules, and Incremental load. These instructions use an example table called [InvoiceLines] and an example date field called [LastEditedWhen].
Prerequisites
In order to support this configuration, you must enable Incremental Load, so the table must have a reliable primary key and field with an incremental value that increases with each insert AND update. This is typically a ModifiedDate field, but other data types may also work as well.
Configuration
- Enable Incremental Load on the table you wish to configure segmented table execution, in this example [InvoiceLines]. The Incremental selection rule MUST be the SAME FIELD used in the project variable in the next step, in this case [LastEditedWhen]. At this point, you should deploy the table, but don't execute.
- This configuration will load data based on the maximum value available in the ODX. So if you prefer to backload all available data you will want to truncate the table during the next execution.
- Create a Dynamic Project Variable called [DynamicCeiling]
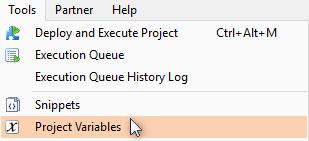
- Type: Dynamic, Resolve: Every Time, Context: ODX
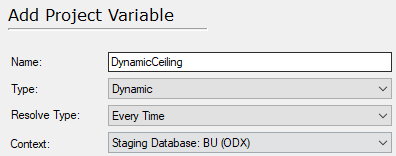
- Click "Script Editor" and insert this script: SELECT ISNULL(DATEADD(month, 1, MAX([LastEditedWhen])),'2000-01-01') FROM [InvoiceLines]
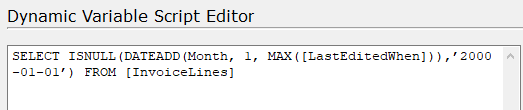
This script will select the greatest value in the [LastEditedWhen] field in the [InvoiceLines] table in the ODX, and add 1 month (This is the segment of data that will be loaded during each execution. You may adjust this increment as desired). If the table is empty it will use the static date of 2000-01-01. This static date should be updated to your desired value, hypothetically 2 weeks after the earliest ModifiedDate in the source table. NOTE: The date field used in this script must be the same field used as the incremental selection rule on the table.
- Be sure to click the “show value translation” radio button to validate the script is working correctly. If the table is empty, the result should be your static value. If correct click OK and return to the project.
- Add a Custom Data Selection Rule on the desired table [InvoiceLines] in the data source.
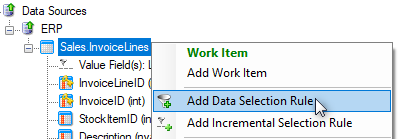
- Drag in the same Date field used previously from the right side pane, type "<=" (less than or equal), then drag in the project variable from the right side pane. IMPORTANT: you must place single quotes around the variable in the script. Your custom data select rule should look like this:
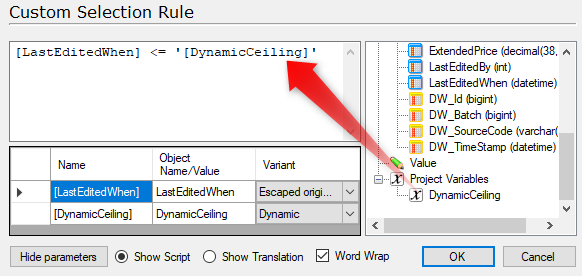
With this configuration, during every execution, TimeXtender will check for the maximum value in this date field in the ODX. It will then add 1-month to that date and only load records within that segment. Loading 1 additional month of data with each subsequent execution. Your source table should now look like this:

NOTE: If you DO NOT wish to load the table from the earliest date available in the source you must add an additional data selection rule to the table. For example, if you only wanted to load data after the year 2004 you could add an additional constraint to the existing data selection rule such as LastEditedWhen <= 2005-01-01.
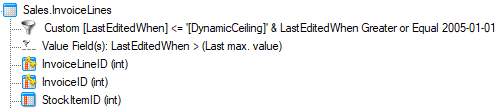
Execution
- Include all three tables (ODX, DSA, and MDW) in a single execution package. With this configuration, all three tables will load the same segment of data configured in the ODX.
- Finally, you can schedule this execution package to recur using your desired frequency. After enough subsequent executions, this table will be fully backloaded with all data in the source.


2 Comments