This article describes a few scenarios on concurrency and parallel processing of tasks as well as expected behavior in TimeXtender and ODX.
Symptoms:
You experience sporadic failures within the ODX load from source systems. The sources vary and there is never a consistent table/connection that is failing. The tables do pass when executed manually.
You notice intermittent errors during scheduled execution of the tasks. However, re-execution of a task works OK without failure. You feel it is related to throughput or table locking (concurrency) but not a communication issue.
Which data transfers involve ODX ?
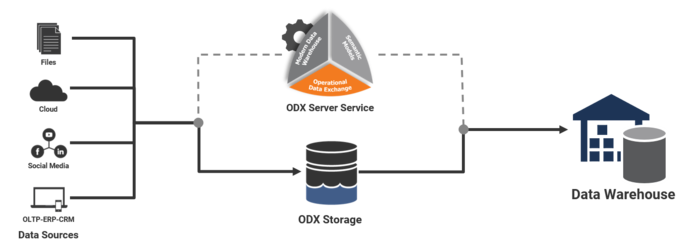
The ODX Server Service handles both inbound and outbound ODX transfers. So, if a data warehouse table is sourced from the ODX, anytime that table is executed, the ODX Transfer step is accomplished by the ODX. In other words, any table which shows a mapping to ODX source will invoke ODX when it is Executed.
1. Source table data extraction to ODX storage (on Data Lake or SQL storage) - triggered by an ODX task, running manually or scheduled.
2. Transfer from ODX storage to a staging Data Warehouse - triggered by an Execute operation on Data Warehouse object (manual, queued or scheduled package).
Reference Architecture with Azure SQL DB
Reference Architecture with On-Premise SQL Server
Settings to control concurrency
1. Concurrent execution threads in each ODX data source "Advanced Settings".
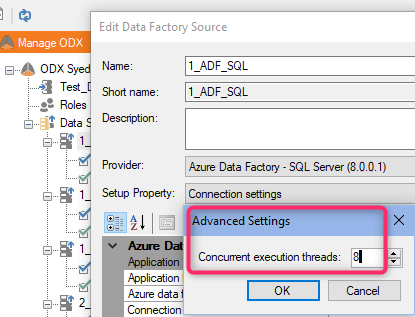
- number of threads on execution packages (including the default package) containing stage tables
- number of ODX tasks set to run at the same time a 'high-thread' execution package runs.
- currently running TX and ODX helper processes in Task Manager
- schedules of tasks in ODX data sources and Execution packages - try to adjust the timing of certain scheduled task to not overlap with other tasks or outbound stage transfer.
4. How much data is being extracted/ transformed on these tasks/connections?
Depending upon the architecture and data passing through the ODX machine, monitor its baseline and peak performance to determine if an alternate design or scaling of CPU/ Memory may help.
How to analyze concurrency in ODX
- Review statistics in ODX backlog: How to Query ODX local Backlog SQLite database
- Review statistics in your local Repository SQL database:
By using the SQL script from Execution Details SQL Query article, you can view, sort and filter through all executions. If you experience an error, review other concurrent tasks running at the same time.
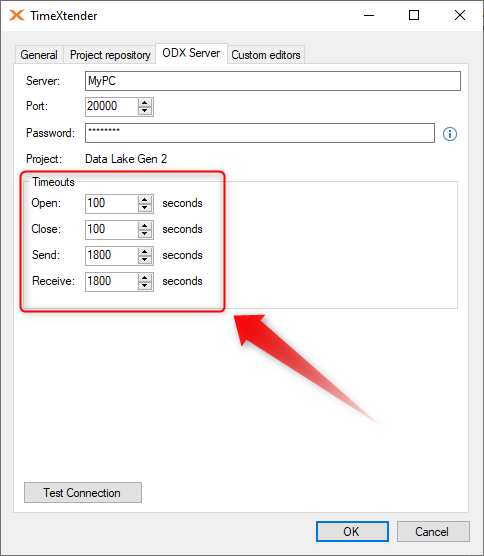
How to increase timeout for ODX data source, ADLS and ADF
1. ODX settings
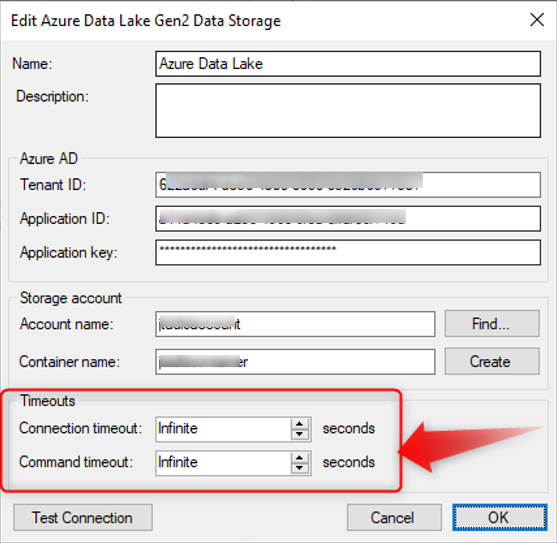
2. For very large data transfers, set the timeouts on the Data Lake storage to Infinite (-1):
3. When using Azure Data Factory to connect to and on-premises SQL (via Self Host Integration Runtime) and extracting large number of rows, if you get a timeout error (similar to the following):
timeout (30000 milliseconds) was reached while waiting for a transaction response from the TimeXtender_ODX_Service_20.10.12 service.
or
System.Net.Http.HttpRequestException: Response status code does not indicate success: 500 (Operation could not be completed within the specified time.).
- open the ADF data source settings in TimeXtender ODX
- Increase Connection timeout from 30 to 7200.
FAQ on concurrency and parallel processing
How many tasks can I run in parallel in ODX, when I have multiple data sources and multiple tasks inside each data source?
For a specific data source, you can run only 1 task at a time. If you run multiple tasks there, the first task will run and the rest would wait (i.e. pending).
Multiple data sources can run 1 task each at the same time. So, if you have nn data sources, each may run 1 task at the same time, making a total of nn tasks running in ODX.
At some point, the number of parallel tasks will be limited by your machine capacity. Resize the VM running the ODX Server, to increase the number of vCPUs, and the number of concurrent tasks allowed
Two data sources extract data from the same table in a source database. Can I run an ODX Transfer task in each data source at the same time?
Yes.
Can I Execute a default or named package in my Data Warehouse (manual or Scheduled) at the same time when ODX tasks are running? Both the ODX task and Execution package operate on same table in various stages. ODX stores data on a data lake.
Yes, you can. Ideally, it should not cause an error.
But the package may wait if it depends on completion of ODX task. If ODX task is extracting new data into its storage, the Execution package will NOT fetch data from the "previous" (existing) version of table from the data lake. It will wait until ODX task fetches new version of data into data lake, then the Execution package will pull the new data into Data Warehouse.
In a large project with concurrent tasks using multiple threads and package executions, I sometimes experience intermittent "database is locked" errors . What is the likely cause? Is there a "collision" of tasks and packages?
The local SQLite backlog isn't built for heavy concurrency. As the number of tasks and package executions grow, even simple transactions might take a while to complete. This may cause waiting threads to timeout, leading to the "database is locked" exception.
Check the Backlog file (database) size and count the number of rows in the following tables:
[ExecutionLogs]
[ExecutionTasks]
[ServiceLogs]
How does "Multiple threads" setting in ODX task or Execution package contribute to concurrency?
Each thread may fetch a different table at the same time.
Does reducing "Multiple threads" setting helps resolve some errors with concurrent tasks, multiple threads and package executions ?
Yes.
How many Execution packages (manual or scheduled) should I run at the same time in Development environment?
only 1
The check that looks for currently running packages - only applies to scheduled instances of an execution package. If you also start a scheduled package manually, the scheduler will not recognize it. In that scenario, both the manual and scheduled version of the execution may run at once. This overlap may cause unexpected results. Potentially, it might cause deadlocks and/or 'faulty' data due to execution not performed in the correct order. Consider the two execution packages as one where individual constraints are unknown.
How does the scheduler service work?
Study this article How does the scheduler service work?
The Scheduler Service checks for scheduled execution packages for every project in its environment every two minutes. When it makes this check, it applies two restrictions:
- The service only runs one execution package per project per check
- The service will not start an execution package if a previously scheduled execution of that package, or any package in that project is still running.
I have 1 environment (Dev) with nn projects, each project has 1 package scheduled to run at the same time. Will the scheduler service run nn packages at the same time?
Yes, if the Scheduler service has been applied and running on Dev.
Warning: Even if packages from separate projects are running at the same time (or Concurrent packages set to run in one project), ensure those packages are not operating on the same tables.
I have 3 environments (Dev, Test, Prod) with Business Unit (no ODX) with Scheduler service is running in each. Can each environments run an Execution package at the same time?
Yes, but consider the pressure put on the source systems as you are reading the same data from 3 different environments at the same time.
I have 3 environments (Dev, Test, Prod) with common ODX data sources. Scheduler service is running in each environment. Can each environments run an Execution package at the same time?
Yes - please see previous question.
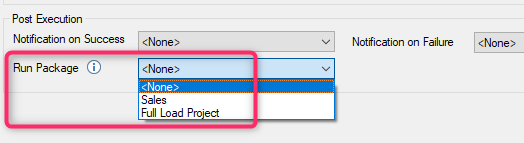
How to sequence packages to run one after another?
Edit package settings, In the Post Execution section, Run Package option, select the next package name.
I have nn packages scheduled to run repeatedly with short intervals. How does TimeXtender pick a package to run? Does that "collide" with ODX tasks?
Study this article How to configure long-interval scheduling
TimeXtender Scheduler service only runs one package per project per starting time. To avoid possible conflicts, be sure to space the scheduled start times of each of your packages by at least five minutes from one another.
Some of my packages are blocked (not running as expected). How do I clean up my scheduled execution ?
Study these articles:
Scheduled Execution issues - Did it not start, did it fail, or is my execution still running?
Is my scheduled execution running
I see a number of ExecutionEngine_x64 processes running in Task Manager when I run many ODX tasks
Those are helper processes launched by ODX.

Performance optimization:
Transfers from ODX (ADLS storage) to Stage - the ODX attempts to download the parquet files from Data Lake into memory on the VM, then write those back to the SQL database.
You have a few options to optimize:
- Use Azure Data Factory (ADF) to transfer from ODX to Stage - This may significantly increase speed but may come with a minor cost for the Azure resource.
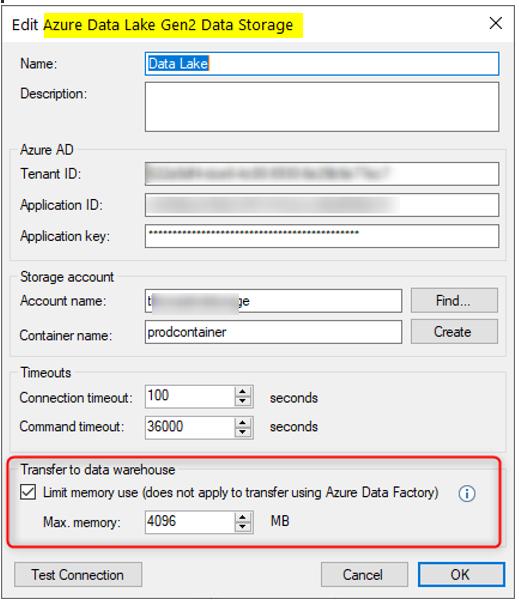
- Increase the Memory Limit on the ODX Data Lake Storage account. For example, if it was set to 8 GB of your 14 GB available on the server, you could increase it to 10-12 GB. This should increase transfer speed slightly without any extra cost. This feature was added in ODX version 20.10.13 ( 9033: Added an option to reduce memory consumption when transferring data from parquet files to SQL MDW through the ODX server
Limit memory consumption by subdividing parquet extraction into multiple column groups. )
3. Increase threads. Test your scenario with 2-6-10 thread etc. and see which setting works best.
4. Increase the Azure SQL database Compute tier. Review Azure metrics. if your SQL database is maxing out at times, more compute resources could be utilized, but it may increase cost.
0 Comments